计算机学院张铭教授团队与DeepSeek合作的论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》原生稀疏注意力模型获得自然语言处理顶会ACL 2025最佳论文奖!
原生稀疏注意力(NSA)通过专注于最关键的组件来优化注意力机制,从而减少不必要的计算。该论文的研究结果对传统的注意力机制提出了挑战,并主张在人工智能模型中向效率转变,因其在长文本处理方面的革新潜力以及在现代 GPU 上性能的提升而备受赞誉。
本届ACL总投稿数量创下历史新高,达到了8360篇论文!(去年只有4407篇)
其中,主会录用率为20.3%,共有1699篇论文;Findings录用率为16.7%,共有1392篇论文。
本次ACL共有4篇最佳论文,2篇最佳社会影响力论文,3篇最佳资源论文,3篇最佳主题论文,26篇杰出论文,以及TACL最佳论文,最佳Demo,时间检验奖等若干奖项。
4篇最佳论文中,另有一篇来自北京大学人工智能研究院助理教授杨耀东团队的大模型对齐抗拒演讲,还有一篇来自斯坦福大学和Cornell Tech团队揭示大模型“差异感知”局限,最后一篇来自 CISPA 亥姆霍兹信息安全中心、TCS Research和微软团队关于大模型采样机理的研究。

图1. ACL 2025最佳论文奖
论文独立一作为北大计算机学院刚刚硕转博的袁境阳同学,主要研究方向是高效大语言模型和稀疏注意力机制,曾获北京市优秀毕业生、北京大学优秀毕业生等荣誉。在NeurlPS, ACL, ICML, ACM MM等多个计算机顶会上以第一作者身份发表论文,谷歌学术被引用5000余次。袁境阳目前在DeepSeek实习,作为核心贡献者参与了DeepSeek-V2、DeepSeek-V3、DeepSeek-R1及等多个业界领先的大语言模型的研发工作。论文第四作者罗钧宇为北大计算机学院博士生,已在人工智能顶级期刊与会议(CCF-A)上以第一作者身份发表了十余篇论文,谷歌学术被引630余次。

图2:ACL 2025颁奖仪式当场的三位北大作者
两位北大博士生的导师张铭是论文的共同通讯作者,发表科研学术论文300多篇,谷歌学术被引用23000余次。曾获得机器学习顶级会议ICML 2014惟一最佳论文奖,网络信息处理顶级会议WWW 2016最佳论文提名、数据挖掘顶级会议ICDM 2022最佳论文提名。发表于WWW 2015的LINE算法是图神经网络著名的基准模型,目前单篇被引超过7000余次。

图3. 论文一袁境阳同学表示稀疏注意力模型是未来长文本处理的重要途径
最佳论文:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
作者:Jingyang Yuan1,2, Huazuo Gao2, Damai Dai2, Junyu Luo1, Liang Zhao2, Zhengyan Zhang2, Zhenda Xie2, Y. X. Wei2, Lean Wang2, Zhiping Xiao3, Yuqing Wang2, Chong Ruan2, Ming Zhang1*, Wenfeng Liang2*, Wangding Zeng2*
1Peking Unviersity 2DeepSeek-AI 3University of Washington
通讯作者: Ming Zhang<mzhang_cs@pku.edu.cn>, Wenfeng Liang <wenfeng.liang@deepseek.com> and Wangding Zeng <zengwangding@deepseek.com>
演讲者: Jingyang Yuan <yuanjy@pku.edu.cn>
机构:北京大学,DeepSeek,华盛顿大学
长文本处理能力是新一代语言模型的关键需求,但传统注意力机制带来的巨大计算开销一直是一个棘手的问题。在这种背景下,稀疏注意力机制展现出了提升计算效率同时又能保持模型性能的巨大潜力。
北大和DeepSeek提出名为NSA的创新性稀疏注意力机制,它能够原生支持训练,通过将算法创新与硬件优化相结合,实现了高效的长文本处理。NSA采用了动态分层的稀疏策略:在保证全局信息获取的同时,还能够精确捕捉局部细节,这得益于其巧妙结合了粗粒度的令牌压缩和细粒度的令牌选择。
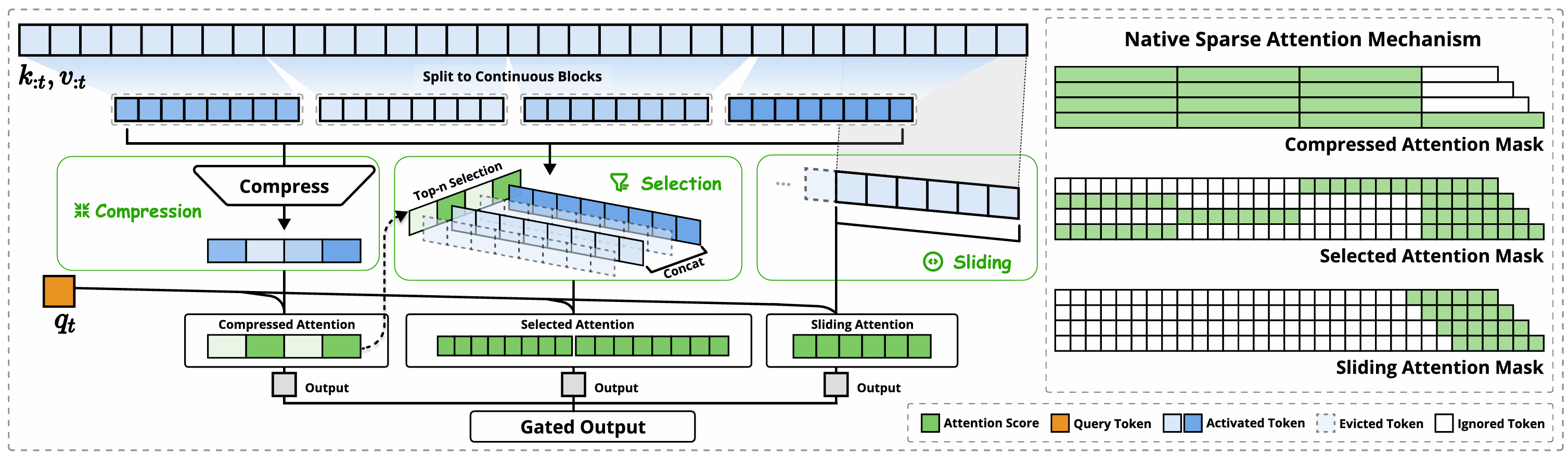
图4. NSA架构: 赋能端到端训练
NSA架构如图4所示,通过三条并行的注意力分支来处理输入序列。对于每一个查询(query),前面的键(key)和值(value)会分别被处理成三种不同的注意力方式:
·压缩注意力(Compressed Attention),用于捕捉粗粒度的整体模式;
·选择性注意力(Selected Attention),专注于重要的词块;
·滑动注意力(Sliding Attention),负责获取局部上下文信息。
每条分支所生成的不同注意力模式。图中的绿色区域表示需要计算注意力分数的部分,而白色区域则是可以跳过、不计算的区域。
NSA的主要创新点有两个:一是通过精心设计的算法平衡了计算密度,并针对现代硬件做了专门优化,显著提升了运行速度;二是实现了端到端的训练模式,在确保模型性能的前提下大幅降低了预训练的计算量。
如图5实验结果显示:采用NSA预训练的模型在通用基准测试、长文本处理和指令推理等多个任务上,性能均达到或超过了使用完整注意力机制的模型。
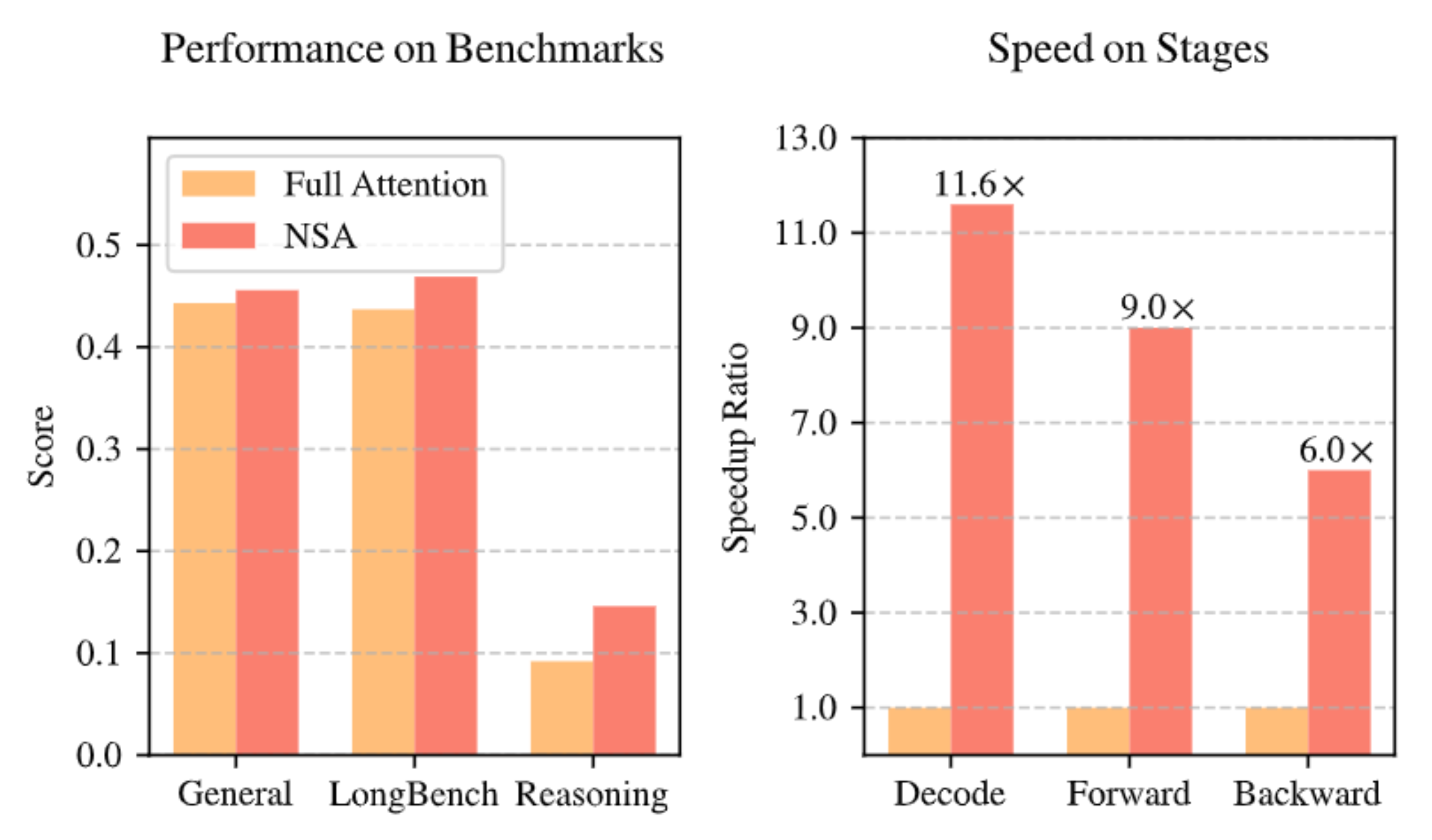
图5. NSA稀疏模型与全注意力模型实验对照
此外,在处理64k长度序列时实现最高 9 倍训练加速和11 倍解码,无论是decoding、前向传播还是反向传播,NSA都展现出了显著的速度优势,充分证明了它在模型全生命周期中的高效性。
该论文2025年2月16日一经发布就引起了国内外学界和业界的广泛关注。NSA是一个专为硬件优化的系统,打破了性能与成本之间的权衡取舍,推动高效大型语言模型的下一个前沿领域。NSA把AI行业的焦点从“模型规模竞赛”拉向“算力效率竞赛”,堪称2025年上半年最具杠杆效应的底层技术突破之一。
参考文献:
1.NSA论文全文https://aclanthology.org/2025.acl-long.1126/
2.袁境阳同学获奖演讲视频链接https://bilibili.com/video/BV1Gv8zzoEcw)
3.2025年7月31日新智元报道《刚刚,北大DeepSeek斩获ACL 2025最佳论文!全网首发一作演讲,稀疏注意力是终局》https://mp.weixin.qq.com/s/3Nez_K7EPBpRp2H1U7kVuw
4.2025年5月19日新智元报道“北大DeepSeek论文或预定ACL Best Paper!梁文锋署名” https://mp.weixin.qq.com/s/GHg4rjtq83bw5W5-HM3I7w


