北京大学杨仝教授团队近期发布了其在高效大型语言模型研究方向的一项新成果——FairyR1-32B-Preview模型。该模型基于DeepSeek-R1-Distill-Qwen-32B基座,通过结合微调与模型合并技术构建。研究探索了在参数量大幅减少的情况下,模型在特定任务上实现与更大模型相当甚至更优性能的可能性。该模型已在北大校园网提供服务,该研究得到了国家自然科学基金委项目(62372009)的资助。
FairyR1模型是在团队前期TinyR1工作基础上进行的进一步探索,沿用了“分合蒸馏”的研究思路,并在数据处理和模型结构上进行了优化。本次工作重点改进了蒸馏数据的构建流程,对来源于例如AI-MO/NuminaMath-1.5(数学)和open-thoughts/OpenThoughts-114k(代码)等数据集的原始数据,通过API生成答案并进行多阶段筛选。筛选过程包括基于API答案的正确性验证(针对数学数据),以及基于长度的筛选(数学数据保留2k—8k tokens范围,代码数据保留4k—8k tokens范围),最终构建了更具针对性的约6.6k条数学数据和约3.8k条代码数据用于训练。在模型结构方面,研究团队尝试仅训练两个领域(数学和代码)的专业模型进行合并,而非此前的3个,旨在进一步优化流程和资源消耗。这两个专业模型在一致的训练参数下(例如相同的学习率和批次大小)独立训练约5个周期后,利用AcreeFusion工具进行了合并。此外,团队也针对用户实际使用体验进行了一定程度的对齐优化尝试。
在多个公开基准测试中,FairyR1展现出了在低参数量下的竞争力表现。以下为FairyR1与DeepSeek-R1-671B及DeepSeek-R1-Distill-Qwen-32B在部分基准上的得分对比:
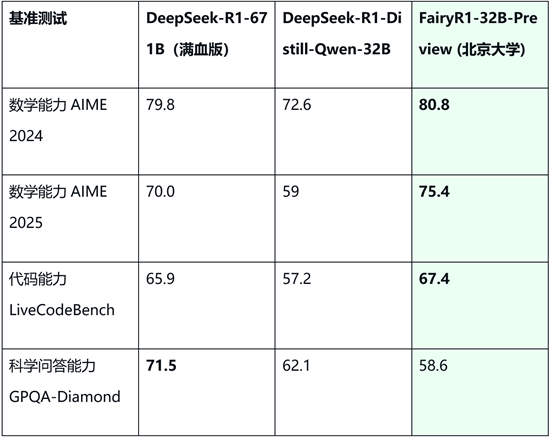
得分对比
从测试结果可以看出,FairyR1在AIME 2025和LiveCodeBench基准上得分略高于DeepSeek-R1-671B,在AIME 2024上表现接近。在GPQA-Diamond科学基准上,FairyR1的得分低于DeepSeek-R1-671B。这些数据表明,FairyR1在采用DeepSeek-R1-Distill-Qwen-32B基座并经过特定技术处理后,能够在约5%参数量的情况下,在数理和编程等领域实现与大型模型相当或略优的性能水平,但在科学等其他领域可能存在差距。
这项工作探索了通过优化的数据处理和模型融合技术,在保证特定任务性能的前提下大幅降低模型规模和潜在推理成本的可能性。
杨仝团队表示,FairyR1模型是探索高效大型语言模型技术路线的阶段性成果。通过对蒸馏和合并方法的改进,团队希望验证在有限资源下实现高性能模型的可行性。

团队成员李旺、周俊廷、刘文睿、杨仝合影


