国际计算机视觉与模式识别会议(CVPR)2024即将于6月17至21日在美国西雅图召开,CVPR是计算机视觉乃至人工智能领域最具学术影响力的顶级会议之一,在Google Scholar指标榜单中位列全球学术出版物第4。本年度召开的CVPR 2024 共收到11532篇投稿,其中2719篇被接收,录取率为23.6%,接收论文中324篇(11.9%)被选为Highlight,90篇(3.3%)被选为Oral。
据不完全统计,北京大学计算机学院在本年度CVPR会议中发表论文44篇,其中36篇来自视频与视觉技术研究所,5篇来自前沿计算研究中心,数据科学与工程研究所、计算语言学研究所和元宇宙技术研究所各有1篇论文发表,研究方向涵盖计算摄像、脉冲视觉、多模态大模型、三维视觉、具身智能、扩散模型等计算机视觉前沿方向。
以下是对部分论文的简要介绍(按照研究所和作者名字首字母排序):
一、 事件相机引导的直接和间接光照分离
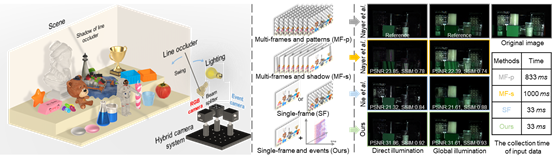
场景物体反射光照中包含直接光照和间接光照两部分,直接和间接光照的分离是计算机视觉中一个经典任务,可以提高形状恢复和物体材质估计等下游任务的准确度,例如光度立体视觉、结构光扫描等。当前直接和间接光照分离方法大多需要较长的数据拍摄时间,只能应用于静态场景,无法迁移到动态场景当中。现有单图方法虽然数据拍摄时间短,但由于缺少物理约束其分离效果较差。为了解决该问题,CVPR 2024论文《EvDiG: Event-guided Direct and Global Components Separation》(Oral)提出事件引导的直接和间接光照分离方法EvDiG,从单张传统RGB图像和对应记录阴影变化的事件信号实现直接和间接光照的分离。该方法利用事件相机高时间分辨率的特点,记录快速投射阴影变化下场景亮度的连续变化信息,从而获取场景光照物理约束,并以此实现场景直接和间接光照的分离。实验结果表明,在仅有单张图像和事件作为输入下,EvDiG在直接和间接光照分离效果上接近多图传统方法。通过控制光源遮挡物的快速运动,可以极大地缩短数据拍摄所需要的时间,达到单图RGB图像所需拍摄时间的水平。EvDiG可迁移到动态场景当中,实现动态场景下的直接和间接光照分离。
该论文所有作者均来自于北京大学,第一作者为周鑫渝,通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括段沛奇、李博宇、周矗和许超教授。
二、 基于事件相机的实时光度立体视觉
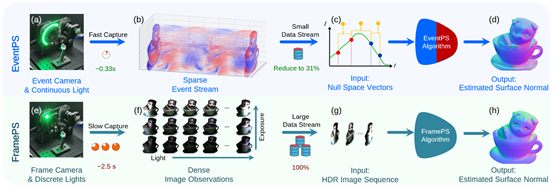
光度立体视觉是一种通过分析从各个方向照射物体的图像序列来估计物体表面法线的技术,其独特之处在于重建结果的高分辨率和精确细节。在密集采样光照和朗伯反射物体的条件下,光度立体视觉方法的优势尤为突出。传统的基于帧相机的光度立体视觉数据采集过程复杂且耗时,通常需要捕获多曝光图像来合成高动态范围图像,从而准确地捕获物体表面的镜面反射区域,严重阻碍了有实时性需求的应用。事件相机具有高时间分辨率、高动态范围和低带宽要求的特点,被认为是实时计算机视觉应用中一种有前景的数据采集方案。CVPR 2024论文《EventPS: Real-Time Photometric Stereo using an Event Camera》(Oral)利用事件相机的独特属性实现了实时的光度立体视觉。从事件相机触发的基本模型出发,逐个事件推导出与表面法线直接相关的“零化向量”信息。在传统算法与深度学习算法领域分别实现了基于事件相机的光度立体视觉算法。配合高速转台进行数据采集和经过GPU优化的算法,实现了超过30帧每秒的实时表面法线重建。
该论文第一作者为于博涵(北京大学),通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括任杰骥(上海交通大学)、韩金(东京大学)、梁锦秀(北京大学)和王非石(北京大学)。
三、 利用近场和远距光源的三维场景逆渲染重建
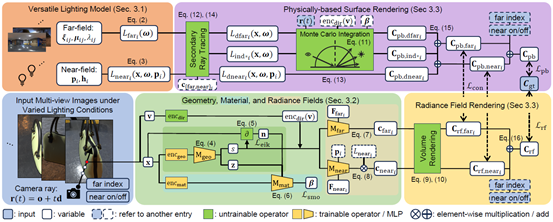
在当今的数字时代,随着电影制作、游戏开发、VR/AR技术的飞速发展,对于在虚拟世界场景中绘制具有真实感和多样性的虚拟三维物体的需求日益增长。通过使用多视角二维RGB图像作为输入,三维重建技术能够花费较少的时间和精力地创造三维物体,从而成为解决该需求的一大途径。逆渲染三维重建方法能够在重建过程中将环境光照与物体材质属性分离,在任意光照条件下进行重建物体的准确渲染,相比一般三维重建方法更适用于产业中的多种应用场景。现有的逆渲染三维重建技术已经尝试采用多种光照下的观测对场景的光照与材质进行解耦,但是大多只能支持远距光源下的观测,无法对可控的近场光源(如闪光灯)进行更有效的利用以得到更加精细而准确的物体材质。为了解决该问题,CVPR 2024论文《VMINer: Versatile Multi-view Inverse Rendering with Near- and Far-field Light Sources》(Highlight)提出利用近场和远距光源的三维场景逆渲染重建方法,可以利用输入图像中包含的所有远距和近场光照条件,进行光照和材质间的消歧,因此能够更加有效地利用可控的光源(如与相机并置的闪光灯或固定位置的台灯)和不同的远距环境光照条件,得到更加精细而准确的物体材质重建。实验表明,该方法可以有效利用各类光源下的观测,其重建结果的准确度与速度均超过了现有的最先进方法。
该论文第一作者为费凡(北京大学),通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括汤佳骏(北京大学)和谭平教授(香港科技大学)。
四、 面向去模糊和插帧任务的低光下事件相机延迟校正
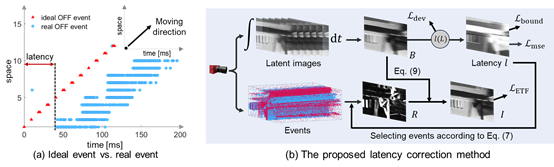
在低光场景下,基于事件相机的去模糊和插帧算法在建模中均需要假设理想的事件触发模型,即事件检测时间与实际变化发生时间一致。在低光场景下,真实事件模型与理想事件模型存在较大的偏差,导致去模糊和插帧算法的建模不够准确,极大影响了这些算法的性能。目前尚不存在事件相机的延迟矫正算法,因此低光下基于事件相机的去模糊和插帧算法的退化问题未能被充分考虑。针对上述问题,CVPR 2024论文《Latency Correction for Event-guided Deblurring and Frame Interpolation》提出了基于事件的时序置信度指标,用于评估去模糊后图像的清晰程度,判断去模糊算法的效果;该论文还提出了一个基于延迟与强度值的曲线,建模了延迟与模糊图像强度值的关系;基于时序置信度指标、事件积分的可导表达及上述曲线,该论文实现了数据驱动的事件延迟矫正。实验结果表明,该论文提出的方法能够校正事件相机的延迟,在一定程度上解决低光下基于事件相机的去模糊和插帧算法的退化问题。
该论文第一作者为杨溢鑫(北京大学),通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括梁锦秀(北京大学)、于博涵(北京大学)、陈岩(商汤科技)和任思捷(商汤科技)。
五、 基于滚动混合比特脉冲的高帧率高动态视频
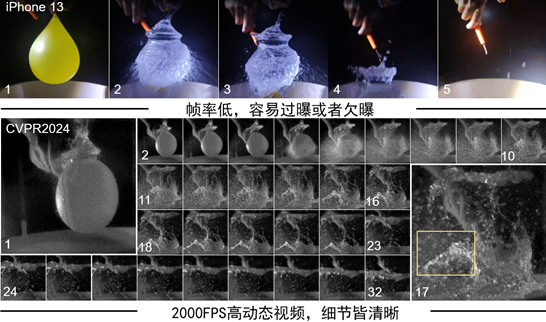
脉冲相机是受灵长类动物视觉系统启发而发明的新型高速成像设备,其能够对到达像素点的光子不断积分,当光子累积的能量达到既定阈值后,该像素点发放一个单比特脉冲。对累积的光子能量进行单比特量化,相较于多比特量化,能够有效降低数据传输压力、有力保障脉冲信号的高速读出。但单比特脉冲所能表征的环境光动态范围受到了一定制约,这是因为对高动态范围(High Dynamic Range, HDR)的精细化记录依赖于高位的多比特数据。对于存在高速运动的高动态范围场景,是否可以实现既要高帧率(High Frame Rate, HFR)使之看得快,又要高比特位使之看得清的脉冲成像?CVPR 2024论文《Towards HFR and HDR Video from Rolling-Mixed-Bit Spikings》提出了一种采用滚动混合比特方式读出脉冲信号的相机工作模式,该模式通过在单比特脉冲信号中循环滚动读出多比特脉冲,从而保留了少部分稀疏的多比特脉冲信息。之后,通过对单比特高速脉冲进行光流估计,实现对稀疏的多比特脉冲信号进行上采样插值,获得与单比特脉冲信号同等稠密程度的多比特脉冲信号。最后,通过将多比特信号与单比特信号进行时空维度的融合,重构得到每秒2000帧的高动态范围视频。实验表明,该论文提出的方法能够在只增加约2%数据冗余的条件下,达到媲美于完全三比特脉冲的高动态重构视频效果。同时对比传统基于帧的商业相机,该论文提出的方法在连续记录高速运动场景方面存在潜在优势。
该论文的共同第一作者为常亚坤副教授(北京交通大学;原北京大学博雅博士后),叶力多斯·肖开提(北京大学),通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括刘俣伽博士(北京大学)、樊斌博士(北京大学)、黄兆鋆(北京大学)和黄铁军教授(北京大学)。
六、 语言引导的图像反射分离
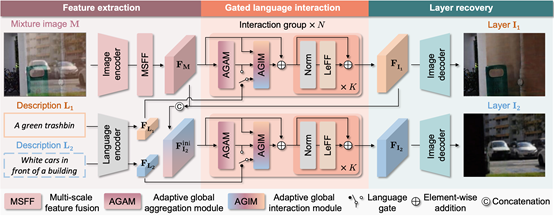
玻璃反射的存在会显著降低捕获图像的图像质量,并干扰下游的计算机视觉任务,如人脸识别或深度估计。图像反射分离方法可以将带反射干扰的混合图像分解为位于玻璃不同侧面的场景,即反射层和背景层。当前方法主要是采用专门的拍摄装置来获取多张信息互补的场景图像从而分离反射,或者是利用从统计特性中得到的人工先验来学习反射的知识。这两类方法要么由于数据拍摄的高要求限制了应用范围,要么是缺乏足够的关于发射层和背景层的辅助信息导致鲁棒性不够。为了解决这个问题,CVPR 2024论文《Language-guided Image Reflection Separation》首次提出了使用语言引导图像反射分离,利用灵活的自然语言来指定混合图像中一层或两层的内容,减缓了反射分离问题的不适定性,保证了对实时捕获或在线下载的混合图像的泛化性。该方法使用自适应全局交互模块来保持整体语言和图像内容的一致性,并利用专门设计的损失函数来约束语言描述与不同图像层之间的对应关系,通过提出一种语言门机制和随机化训练策略来解决可识别层模糊问题。在手动标注了语言描述后的真实反射分离数据集上进行实验,该方法在多个数据集上的表现超过了现有的最先进方法。
该论文所有作者均来自于北京大学,共同第一作者为钟灏峰和洪雨辰,通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括翁书晨和梁锦秀博士。
七、 窄带图像引导的大气扰动消除
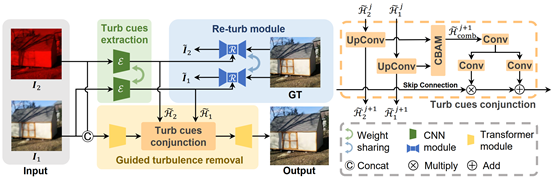
在远距离成像中,大气扰动的消除对于提升成像质量至关重要。由于图像内容和复杂的扰动场难以精确区分,现有基于单图输入的扰动消除方法在处理复杂扰动场景时遇到瓶颈。为解决这一问题,一些方法提出利用大气扰动的时变物理属性,基于多图输入进行扰动的消除。尽管此类方法通常在细节恢复能力和鲁棒性上表现较好,但其需要拍摄图像序列来获得足够的大气扰动消除约束,在实际应用中可能会带来不便。为解决真实场景中的大气扰动消除问题,CVPR 2024论文《NB-GTR: Narrow-Band Guided Turbulence Removal》提出了一种新的湍流去除网络。作者发现窄带图像的通带上累积扰动效应减少,可以为扰动消除过程带来强有力的约束,为此提出在传统的RGB图像下引入了额外的窄带图像的引导,仅需一对图像即可显著抑制大气扰动,从而增强了捕获场景的清晰度和真实性。该方法采用两步融合策略,首先利用再扰动模块有效地从一对RGB和窄带图像中联合提取扰动场信息,再据此有效引导扰动消除网络。利用窄带成像的优势,图像平面的湍流得到显著降低,从而能在不损失色彩信息的同时减少高频细节的丢失。实验结果表明,该方法在保持单图扰动消除方法的便利性的同时,能够产生更真实的结果。
该论文所有作者均来自于北京大学,第一作者为夏一飞,通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括周矗、朱成轩和许超教授。
八、 传统图像和事件信号互补的鲁棒手势识别
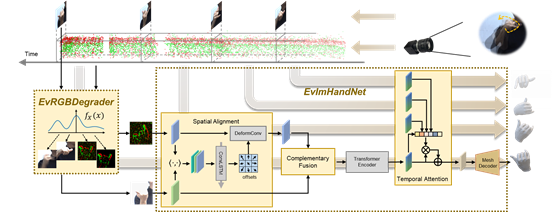
手势姿态估计是一个经典的计算机视觉问题,在人机交互、虚拟现实和机器人领域中有重要应用,一个实用的手势姿态估计算法需要做到鲁棒性和泛化性强、延迟和功耗低。当前的手势姿态估计方法主要是基于RGB或者RGB-D相机,RGB相机的成像具备丰富的颜色和纹理信息,但是面临着信息冗余、成像延迟,在挑战性场景下图像质量的退化(过曝或者运动模糊)等问题。而事件相机的异步成像机制使其具备高动态范围、低延迟,低数据冗余度等特征,但同时也存在数据稀疏纹理缺失的问题。针对这些问题,CVPR 2024论文《Complementing Event Streams and RGB Frames for Hand Mesh Reconstruction》提出利用事件相机和RGB相机成像的互补性,融合两种模态数据进行手势姿态估计。数据方面,本工作根据两种相机的成像特性,提出了一种成像退化的数据增广方式,使得训练时只需要正常场景的数据,就可以泛化到挑战性场景上;模型方面,本工作精心设计空间对齐、互补融合、以及时序注意力模块,将两种模态对齐。实验结果表明,该方法效果优于基于单个传感器的方法,只需要常规场景的训练数据,就可以泛化到各种挑战性场景。
该论文共同第一作者为蒋建平(北京大学)和周鑫渝(北京大学),共同通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所)和邓小明研究员(中科院软件所),合作作者包括王炳宣(北京大学)、和许超教授(北京大学)。
九、 基于神经辐射场的水下场景表征方法

神经辐射场可以从多视角的二维图片信息中学习并生成三维的场景表征模型。对于多数常见的场景,神经辐射场均被证明是有效的。然而,水下场景中包含的诸多动态成分,包括水对光的吸收与散射性质、局部光照的变化以及场景中运动的物体,为其表征带来了独特的挑战。现有的基于神经辐射场的场景表征方法并未充分考虑上述动态成分,导致水下场景三维重建质量较低。为了解决上述问题,CVPR 2024论文《Neural Underwater Scene Representation》提出在传统的神经辐射场框架上进行扩展,对水下场景中水体性质、不稳定的光照条件和运动的物体分别建模,实现高质量水下场景的表征。该方法采用了混合渐进的采样方法与两阶段的网络训练策略,实现了对网络中各项参数的鲁棒优化。实验结果表明,该方法在不显著延长训练与渲染时间的基础上,对水下场景表征的精确度超过了现有的最先进方法。该方法也可以应用到场景编辑的各项任务中,为水下图像恢复和水体迁移任务提供便利。
该论文共同第一作者为汤云开(北京大学)和朱成轩(北京大学),共同通讯作者为施柏鑫长聘副教授(北京大学计算机学院/视频与视觉技术研究所)和万人杰助理教授(香港浸会大学),合作作者包括许超教授(北京大学)。
十、 粗糙度和透明度可度量的光度立体实拍评测数据集

实拍数据集对于评测光度立体视觉算法的在真实世界中的性能表现、探知光度立体的研究前沿有着重要意义。现有的实拍光度立体数据集对于表面反射的控制及评测基于语义描述,例如“塑料”,“陶瓷”等,无法给出光度立体在定量化表面反射方面的性能评估。同时,由于语义描述难以度量,光度立体视觉算法的评测结果无法推广到实拍数据集中未包含的材质反射。因此,现有数据集及其评测结果难以在实际应用场景中为不同反射物体提供光度立体算法选择的参考。针对这一问题,CVPR 2024论文《DiLiGenRT: A Photometric Stereo Dataset with Quantified Roughness and Translucency》提出了可度量粗糙度和透明度的光度立体实拍数据集。受图形学领域参数化表面反射模型的启发,本工作基于可量化的材质反射参数(粗糙度,透明度)来构建数据集。通过使用6种不同浓度的溶液在9个不同粗糙度的球状模具中固化,构建了6x9个透明度和粗糙度可控的半球数据集。基于该数据集进行光度立体算法评测不仅定量化回答了算法在材质反射方面的工作区间,还可以通过粗糙度和透明度数值差值的方式推测现有光度立体算法在未包含材质反射下的性能表现。
该论文的共同第一作者为郭亨特聘研究员(北京邮电大学)、任杰骥博士(上海交通大学)、王非石(北京大学),共同通讯作者为施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所)和任明俊教授(上海交通大学),合作作者包括Yasuyuki Matsushita教授(大阪大学)。
十一、 实时人像视频三维感知重光照
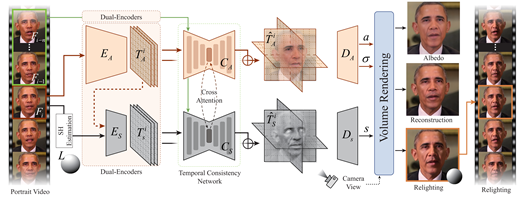
人像视频重光照是计算机图形学和计算机视觉领域中极具应用价值的研究方向。这项技术需要精确建模光线、人脸几何和材质之间的复杂交互作用,并确保合成视频的时间连贯性。为了提供更大的编辑自由度,并在增强现实和虚拟现实等领域得到广泛应用(例如创建能够根据环境调整光照的三维面部模型),需要对人像视频进行三维感知的重光照,也就是将二维人脸信息提升到三维可重光照的表示形式,以便在不同的观察角度和光线条件下重新渲染人像视频。实时处理的需求进一步增加了这一挑战的难度。针对这一难题,CVPR 2024论文《Real-time 3D-aware Portrait Video Relighting》(Highlight)首次提出了一种通过神经辐射场实现人像视频实时三维感知重光照的方法。该方法能够在新视角和新光照条件下实时合成逼真的三维人像,在消费级硬件上实现32.98 FPS的处理速度,并在重建质量、光照误差、光照稳定性、时间一致性和推理速度等方面达到了当前最先进的水平。
该论文第一作者为蔡子祺(北京交通大学;9月份北京大学直博入学),通讯作者为高林研究员(中科院计算所),合作作者包括蒋楷文(加州大学圣地亚哥分校)、陈姝宇(中科院计算所)、来煜坤(卡迪夫大学)、傅红波(香港城市大学)以及施柏鑫长聘副教授(北京大学计算机学院/视频与视觉技术研究所)。
十二、 基于稀疏偏振图像的镜面反射物体三维重建方法
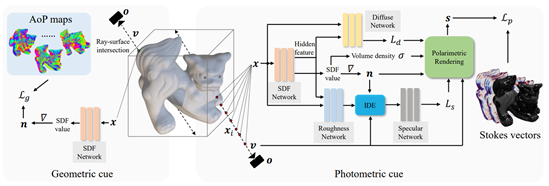
镜面反射物体的三维重建极具挑战性,这是由于物体表面同一点被观测到的结果随视角变化而变化,违反了传统多视角立体技术中的一致性原则。现有方法通过分别估计物体本身颜色和环境光来帮助恢复三维物体结构,通常需要大量的不同视角观测图像作为输入。如果减少输入图像视角,往往会造成重建结果质量下降或无法重建等问题,而现有的稀疏图像三维重建技术多适用于非镜面反射物体。为了解决稀疏视角下的镜面反射物体重建问题,CVPR 2024论文《NeRSP: Neural 3D Reconstruction for Reflective Objects with Sparse Polarized Images》提出了利用偏振图像所提供的光照和几何信息共同约束隐式辐射场表达的法向量,从而能够在稀疏输入视角下高效充分利用图像信息。定性和定量实验表明,该方法在六个输入视角下,相较于现有技术能够获得更加准确的重建效果。此外,该论文提供了第一个包含扫描结果的用于偏振图像三维重建的真实数据集,为未来的研究工作提供了定量分析资源。
该论文共同第一作者为韩雨霏(北京邮电大学)、郭亨特聘研究员(北京邮电大学)、Koki Fukai(大阪大学),通讯作者为郭亨特聘研究员(北京邮电大学),合作作者包括Hiroaki Santo助理教授(大阪大学)、施柏鑫长聘副教授(北京大学/计算机学院视频与视觉技术研究所)、Fumio Okura副教授(大阪大学)、马占宇教授(北京邮电大学)和贾云鹏教授(北京邮电大学)。
十三、 基于旋转光源和自然光条件下的非标定光度立体视觉
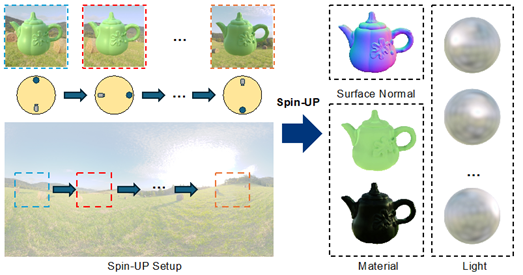
自然光条件下的非标定光度立体视觉克服了传统非标定光度立体视觉以暗室为拍摄环境、以简单光源为光照要求的固有缺点。然而,现有的方法受限于光源和物体之间复杂的相互作用和自然光的多样性,往往只能在特定材质或者满足特定限制的光源下重建物体三维表面。为了解决这个问题,CVPR 2024论文《Spin-UP: Spin Light for Natural Light Uncalibrated Photometric Stereo》提出了基于旋转光源的实验设置和非监督学习的方法。该方法从旋转光源下拍摄得到的图片以及物体的轮廓信息中发掘有关光源的先验,以可微渲染为主要技术手段,配合所提出的优化策略,可以同时还原出物体的三维表面、各向同性的反射率函数以及环境光源。实验表明,该方法在本文提出的合成和真实数据集上重建出了更高精度的三维表面,效果优于目前所有其他监督或无监督的方法,并且可以适配更一般的自然光和物体。
该论文共同第一作者为李宗瑞(南洋理工大学)和陆展(南洋理工大学),通讯作者为郑乾研究员(浙江大学),合作作者包括闫浩杰(浙江大学),施柏鑫长聘副教授(视频与视觉技术研究所)、潘纲教授(浙江大学)和蒋旭东副教授(南洋理工大学)。
十四、 从处理脉冲波动性的角度提升脉冲相机图像重建
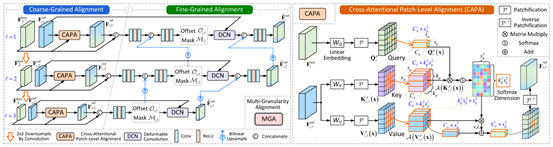
作为一种超高速的仿生视觉传感器,脉冲相机在对高速场景的记录中展现出了巨大的潜力。不同于传统帧式相机,脉冲相机的每个像素通过对光子进行连续累积并发放脉冲来实现对光学场景的记录。在这一过程中,有多种效应会对脉冲相机的成像过程产生影响,包括光子到达的泊松效应、电路的热噪声以及脉冲读出的量化效应。以上因素引入了脉冲的波动性,即使光强是稳定的,脉冲之间的时间间隔也会随时间发生变化,无法准确反映光照强度。CVPR 2024论文《Boosting Spike Camera Image Reconstruction from a Perspective of Dealing with Spike Fluctuations》提出了一种考虑脉冲波动性的脉冲相机图像重建方法。本文首先揭示了脉冲发放的时间差分(DSFT)倒数的无偏估计属性,并基于此提出了一个基于多阶DSFT的表征模块用于抑制脉冲的波动性。此外,本文还提出了一个多粒度的特征对齐模块,用于进一步抑制脉冲波动性带来的影响,其中粗粒度的对齐基于具有局部搜索策略的块级交叉注意力进行设计,精细粒度的对齐基于像素级的可变形卷积进行设计。实验结果证明,本文所提出的方法在合成数据与真实数据上都具有优良的性能。
该论文第一作者为赵睿(北京大学),通讯作者为熊瑞勤研究员(北京大学/计算机学院视频与视觉技术研究所)。合作者包括赵菁、张健助理教授、余肇飞助理教授、黄铁军教授(以上作者均为北京大学),以及范晓鹏教授(哈尔滨工业大学)。
十五、 面向拜耳模式脉冲流的超分辨率重建

脉冲相机是一种神经形态视觉传感器,能够以极高的时间分辨率连续产生表示光子到达的二进制的脉冲流,从而实现对高速度场景的捕捉。目前,为了实现对彩色高速场景的记录,可以通过配备拜耳模式颜色滤光阵列构建彩色脉冲相机。尽管脉冲相机已展现出在高速成像方面的巨大潜力,但与传统数码相机相比,其空间分辨率十分有限。为此,CVPR 2024论文《Super-Resolution Reconstruction from Bayer-Pattern Spike Streams》提出了一种用于从低分辨率拜耳模式脉冲流中重建得到高分辨彩色图像的彩色脉冲相机超分辨率网络。具体来说,本文首先提出了一种面向拜耳模式脉冲流的表征方法,通过结合局部时间信息与全局感知信息来表示该二进制数据。然后,利用颜色滤光阵列的颜色分布与亚像素级的运动信息来寻找每个颜色通道的时域可用像素。为此,本文开发了一个基于残差的特征细化模块以减少运动估计误差的影响。考虑到色彩相关性,联合利用颜色通道的多阶段时空像素特征来重建高分辨率的彩色图像。实验结果表明,所提出的方案能够从低分辨率的拜耳模式脉冲流中重建出具有高时间和空间分辨率的彩色图像。
该论文第一作者为董彦辰(北京大学),通讯作者为熊瑞勤研究员(北京大学/计算机学院视频与视觉技术研究所)。合作者包括张健助理教授、余肇飞助理教授、黄铁军教授(以上作者均为北京大学)、朱树元(电子科技大学)和范晓鹏教授(哈尔滨工业大学)。
十六、 语义频域提示的知识蒸馏
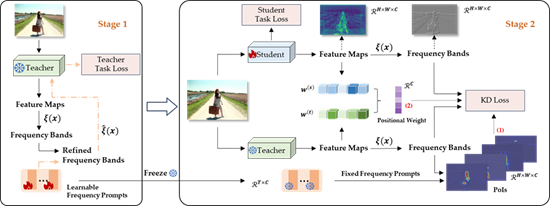
Knowledge distillation (KD)已成功应用于各种任务,主流方法通常通过空间模仿来提升学生模型。然而,在教师模型的空间域中引起的连续下采样是一种图像损坏,阻碍学生模型分析需要模仿的具体信息,导致准确性下降。为了更好理解受损特征图,CVPR 2024论文《FreeKD: Knowledge Distillation via Semantic Frequency Prompt》提出将注意力转移到频域。在频域蒸馏中,面临着新的挑战:低频带传达较少的信息量,高频带更具信息性但仍有噪声,不是每个像素对蒸馏的贡献相等。为了解决上述问题提出将Frequency Prompt插入到教师模型,在微调过程中学习语义信息;在蒸馏期间,通过Frequency Prompt生成像素级的频率掩码,以定位各个频率带内的感兴趣像素(PoIs)。此外,针对密集预测任务采用位置感知关系损失,为学生模型提供高阶空间增强。此知识蒸馏方法被命名为FreeKD,它确定了频率蒸馏的程度与位置。FreeKD不仅在密集预测任务上始终优于基于空间的蒸馏方法(例如,FreeKD使RepPoints-R50在COCO2017上获得了3.8AP增益,PSPNet-R18在Cityscapes上获得了4.55mIoU增益),而且使学生模型更具鲁棒性。值得注意的是,本文还首次验证了在大规模视觉模型(例如,DINO和SAM)上的泛化能力。
该论文第一作者为张袁(北京大学),通讯作者为仉尚航助理教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括黄涛(悉尼大学)、刘家铭(北京大学)、蒋焘(浙江大学)和程宽助理教授(北京大学)。
十七、 面向多模态大模型的端-云协同优化策略
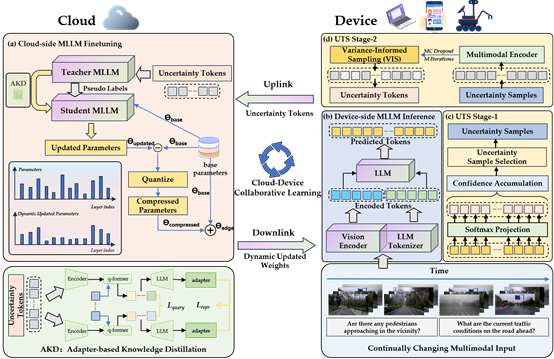
在如今的数字化时代,随着云计算和边缘设备技术的迅猛发展,如何在资源受限的设备上高效部署多模态大模型成为了一个亟待解决的难题。针对这一问题,CVPR 2024论文《Cloud-Device Collaborative Learning for Multimodal Large Language Models》提出了一种创新的云-设备协同持续适应框架(CD-CCA),该框架旨在利用云端大规模多模态大模型(MLLM)的强大能力,提升压缩后设备端模型的性能,从而应对动态变化的环境。在设备到云的上行链路中,采用了一种不确定性引导的Token采样策略(UTS),通过过滤分布外的Token来降低传输成本并提高训练效率。在云端,本文提出了一种基于适配器的知识蒸馏方法(AKD),将大规模MLLM的精炼知识转移到压缩后的设备端模型中。此外,本文还引入了一种动态权重更新压缩策略(DWC),对更新后的权重参数进行自适应选择和量化,从而提高传输效率并减少云端和设备端模型之间的表征差距。实验结果表明,所提出的框架在多个多模态基准测试上优于现有的方法,尤其是在视觉问答和图像标注任务中表现突出。此外,通过真机实验验证了该方法的可行性和实用性。该框架为设备端MLLM在动态环境中的持续适应提供了新的思路,展示了云-设备协同学习的巨大潜力。
该论文共同第一作者为王冠群(北京大学)、刘家铭(北京大学)和李忱轩(北京大学),通讯作者为仉尚航助理教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括张袁(北京大学)、麻俊鹏(中南大学)、魏心宇(北京大学)、张雨泽(北京大学)、庄棨宁(北京大学)、张仁瑞(上海人工智能实验室)和刘一茳(南京大学)。
十八、 面向持续性测试泛化的自适应掩码自编码器
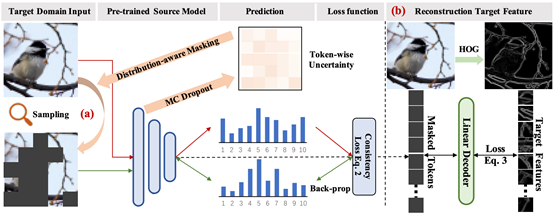
CVPR 2024论文《Continual-MAE: Adaptive Distribution Masked Autoencoders for Continual Test-Time Adaptation》提出了一种面向持续性泛化学习的分布感知掩码自编码器。具体来说,持续性测试泛化(CTTA)旨在将预训练模型迁移到不断变化的目标分布中,以应对真实世界的动态变化。现有的CTTA方法主要依赖于熵最小化或教师-学生伪标签方案,在未标记的目标域中进行知识提取。然而,动态数据分布会导致预测结果校准错误和伪标签噪声,这在现有的自监督学习方法中阻碍了有效缓解错误积累和灾难性遗忘问题。为了解决这些挑战,本文提出了一种全新的持续性自监督方法,即自适应分布掩码自动编码器(ADMA),该方法在增强目标域知识提取的同时,减轻了分布偏移的错误积累。具体来说,提出了一种分布感知掩码(DaM)机制,以自适应地选择掩码位置,然后在掩码目标样本和原始目标样本之间建立一致性约束。此外,对于掩码的特征,利用高效的解码器来重建手工制作的特征描述符(例如方向梯度直方图),利用其域不变性来增强任务相关的表达。通过在四个广泛认可的基准上进行大量实验,所提出的方法在分类和分割CTTA任务中均达到了最先进的性能。
该论文第一作者为刘家铭(北京大学),通讯作者为仉尚航助理教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包徐冉(北京大学实习生)、杨森乔(北京大学实习生)、张仁瑞(港中文)、张启哲(北京大学)、陈泽徽(中科大)和郭彦东(智平方科技)。
十九、 基于梯度的参数选择方法用于高效微调
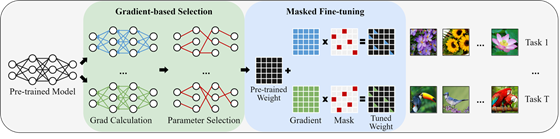
随着预训练模型规模的增长,对于多种下游任务进行完全微调并存储所有参数是昂贵且不可行的。为此,CVPR 2024论文《Gradient-based Parameter Selection for Efficient Fine-Tuning》提出了一种全新的参数高效微调方法,基于梯度的参数选择(GPS),表明了在仅微调预训练模型中少量选择的参数同时保持模型其余部分冻结的情况,可以产生与完全模型微调方法相似或更好的性能。与现有流行的和最先进的参数高效微调方法不同,所提出方法在训练和推理阶段都不引入任何额外的参数和计算成本。另一个优点是模型无关和非破坏性的特性,消除了对于特定模型的任何其他设计的需求。与完全微调相比,GPS在24个图像分类任务中平均仅微调了预训练模型的0.36%参数,在FGVC任务中准确率提高了3.33%(91.78% vs. 88.45%),在VTAB任务中提高了9.61%(73.1% vs. 65.57%)。此外,它还在医学图像分割任务中分别取得了17%和16.8%的mDice和mIoU的显著改善。最后,GPS在与现有参数高效微调方法相比,性能达到了最先进的水平。
该论文第一作者为张智(阿姆斯特丹大学/北京大学)和张启哲(北京大学),通讯作者为仉尚航助理教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括高子俊(山东大学)、张仁瑞(港中文)、Ekaterina Shutova (阿姆斯特丹大学)和周仕佶(清华大学)。
二十、 基于分割一切模型的目标物体三维重建
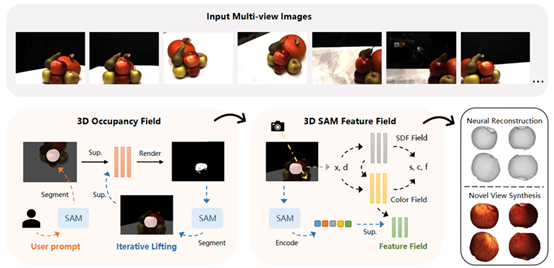
多视角图像的神经三维重建最近引起了越来越多的关注,现有方法通常学习整个场景的神经场,而如何重建用户指定的目标对象仍然是一个未充分探索的问题。考虑到分割一切模型(SAM)在分割任何二维图像方面显示出的有效性,CVPR 2024论文《NTO3D: Neural Target Object 3D Reconstruction with Segment Anything》提出了一种新颖的高质量神经目标对象三维重建方法NTO3D,该方法利用了神经场和分割一切模型的优势。该方法首先提出一种新策略,将分割一切模型的多视角二维分割掩模提升到一个统一的三维占用场。然后,三维占用场被投影到二维空间并生成分割一切模型的新提示。这一过程是迭代的,直到收敛,以将目标对象从场景中分离出来。之后,将分割一切模型编码器的二维特征提升到三维特征场中,以提高目标对象的重建质量。NTO3D将分割一切模型的二维掩模和特征提升到三维神经场,用于高质量的神经目标对象三维重建。本文在几个基准数据DTU、LLFF、BlendedMVS上进行了详细的实验,以展示所提出方法的优势。
该论文第一作者为韦小宝(北京大学),通讯作者为仉尚航助理教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括张仁瑞(上海人工智能实验室)、吴家锐(上海人工智能实验室)、刘家铭(北京大学)、陆鸣(英特尔中国研究院)和郭彦东(智平方科技)。
二十一、 基于自适应思维链的文生图模型提示词分布对齐
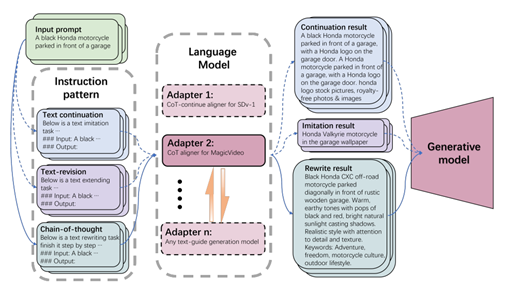
基于扩散的生成模型在生成高保真视觉内容(如图像和视频)方面表现出色。然而, 它们的性能在很大程度上依赖于文本输入的质量,通常称为“提示词”。传统的提示词设 计过程虽然有效,但需要经验丰富的专业知识,对于没有经验的用户来说具有挑战性。CVPR 2024论文《PromptCoT: Align Prompt Distribution via Adapted Chain-of-Thought》提出了 PromptCoT,一种自动优化用户提示词的创新增强器。PromptCoT 基于这样一个观察结果设计:与训练集中高质量图像的文本信息相似的提示词往往会带来更好的生成效果。因此,本文使用一个仅包含高质量视觉内容描述的精心挑选的文本数据集对预训练的大型语言模型(LLM)进行微调。通过这种方式,LLM 可以捕捉到高质量训练文本的分布,从而生成对齐的续写和修订,以提升原始文本。然而,预训练的 LLM 有一个缺点,即它们往往会生成无关或多余的信息,因此采用“链式思维”(Chain-of-Thought, CoT)机制来改进原始提示词与其优化版本之间的一致性。CoT 可以从对齐的续写和修订中提取并整合关键信息,基于上下文线索进行合理推断,从而生成更全面和细致的最终输出。考虑到计算效率,没有为每个单独的模型或数据集分配一个专门用于提示词增强的 LLM,而是集成了适配器,以利用共享的预训练 LLM 作为基础进行数据集特定的适应。通过独立微调这些适配器,可以将 PromptCoT 适应新的数据集,同时最小化训练成本和内存使用。本文中评估了 PromptCoT 在广泛使用的潜在扩散模型上生成图像和视频的表现,结果显示关键性能指标显著改善。
该论文的共同第一作者是姚骏奕(北京大学)和刘一茳(南京大学),共同通讯作者为周大权(字节跳动)和仉尚航助理教授(北京大学/视频与视觉技术研究所),合作作者包括董镇(伯克利加州分校)、郭明非(斯坦福大学)、胡鹤蓝(北京大学)、Kurt Keutzer(伯克利加州分校)和杜力(南京大学)。
二十二、 基于弱监督情绪转换学习的多样化3D协同语音手势生成
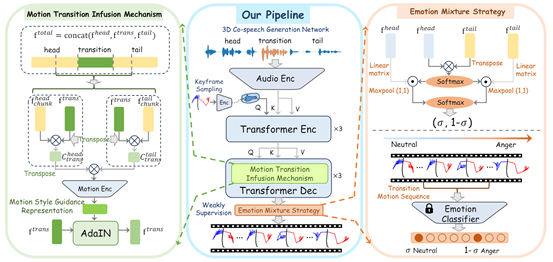
生成生动且富有情感的3D协同语音手势对于人机交互应用中的虚拟头像动画至关重要。虽然现有的方法能够生成遵循单个情感标签的手势,但它们忽略了具有情感转换的长手势序列建模在真实场景中更实用。此外,缺乏具有情感转变语音和相应3D人类手势的大规模可用数据集也限制了该任务的解决。为了实现这一目标,CVPR 2024论文《Weakly-Supervised Emotion Transition Learning for Diverse 3D Co-speech Gesture Generation》首先结合 ChatGPT-4和音频修复方法来构建高保真情感转换人类语音。考虑到获得与动态补全的情绪转换音频相对应的真实3D姿势注释极其困难,本文提出了一种新颖的弱监督训练策略来鼓励权威手势转换。 具体来说,为了增强过渡手势相对于不同情感手势的协调,本文将两个不同情感手势序列之间的时间关联表示建模为风格指导,并将其注入到过渡生成中。本文进一步设计了一种情感混合机制,该机制基于可学习的混合情感标签为过渡手势提供弱监督。最后,本文提出了一个关键帧采样器,可以在长序列中提供有效的初始姿势提示,使得能够生成不同的手势。大量的实验表明,所提出方法优于通过在本文新定义的情绪转换任务和数据集上微调单一情绪对比方法而构建的最先进模型。
该论文第一作者为祁星群(香港科技大学),通讯作者为郭毅可教授(香港科技大学)和柳崎峰教授(香港科技大学)。合作者包括仉尚航助理教授(北京大学/计算机学院视频与视觉技术研究所)以及潘佳豪、李鹏、袁瑞斌、池晓威、李孟非、罗文寒副教授和雪巍助理教授(以上作者均来自香港科技大学)。
二十三、 多模态大语言模型指代感知指令微调方法
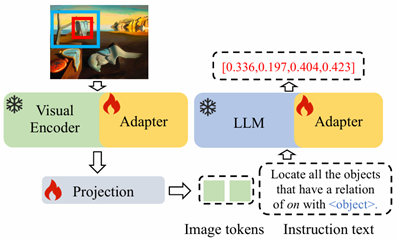
多模态大语言模型是一类以大语言模型为基础集成多种信息模态处理能力的人工智能模型,与传统的多模态模型相比,其利用大语言模型的强大推理能力,在各类视觉任务和多模态理解任务中表现出强大的潜力。 现有的多模态大语言模型一般专注于图像级别的内容理解,无法对图像中的特定目标进行细粒度分析,并且模型构建过程中需要大量的指令微调数据和训练资源,严重限制了其在各类视觉任务和多模态任务中的应用。为了解决这个问题,CVPR 2024论文《Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs》提出了多模态大语言模型指代感知指令微调方法。该方法首先利用现有数据集的标注通过人工设计多样化的指代感知基础任务实现了指令微调数据集构建。为了进一步提升数据的多样性,方法提出了自洽自举的数据生成流程,该流程可以将任意密集目标标注数据集转化为坐标框-描述多模态数据。论文使用适配器同时对视觉编码器和大语言模型进行微调,进一步增加了视觉编码器的细粒度图像理解能力。实验结果表明,该工作使用更少的微调参数量和指令微调数据量,在常规多模态理解任务、视觉定位等指代感知任务和多个多模态大语言模型的评测基准上取得了最好的性能,例如,该工作在常规多模态理解任务GQA上超过使用50M数据的Qwen-VL方法5.2%。在视觉定位等指代感知任务上,在评测基准MMBench上,该工作超过第二名mPlug-Owl 5.6%。
该论文第一作者为轩诗宇(北京大学),通讯作者为张史梁长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括郭清沛(蚂蚁集团)和杨铭博士(蚂蚁集团)。
二十四、 基于多模态定位大模型的可泛化人体关键点定位方法
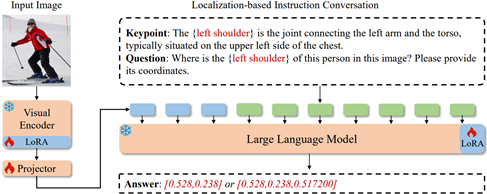
已有人体关键点定位方法从训练数据中学习人体结构先验,进而用于推理未知人体图像输入。这种学习范式的泛化能力受到训练数据的限制,即有限的数据集难以提供通用的人体结构先验,这使得现有方法难以泛化到估计未知数据集人体姿态以及检测新类型的人体结构。为了缓解这一限制并提高人体形态感知方法的泛化能力,CVPR 2024论文《LocLLM: Exploiting Generalizable Human Keypoint Localization via Large Language Model》(Highlight)从另一角度形式化人体姿态感知问题,通过推理人体骨架关键点的文本描述来定位其位置。基于这一思路,提出了首个基于多模态大语言模型的人体姿态感知方法——多模态定位大模型LocLLM。定位大模型将人体关键点定位任务形式化为一个问答任务,通过输入图像、对应的关键点描述以及问题来回答对应的关键点坐标。实验结果表明,本工作在多个人体姿态感知数据集上取得了优异的性能。LocLLM在标准的二维与三维人体姿态估计数据集上取得了77.6%准确率与46.6mm定位误差,超越了传统纯视觉感知方法。在跨数据集泛化测试实验中,LocLLM在Human-Art数据集上取得了64.8%的性能,领先之前最佳方法ViTPose11.0%的准确率。在新类型关键点检测实验中,LocLLM也领先基线方法24.1%的准确率,展现出优异的泛化能力。
该论文第一作者为王东凯(北京大学),通讯作者为张史梁长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括轩诗宇(北京大学)。
二十五、 基于空间感知回归的人体关键点定位方法
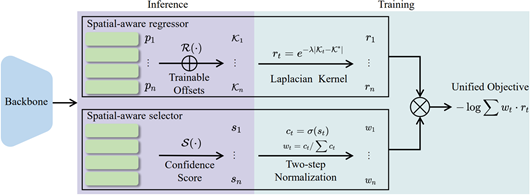
针对现有人体关键点定位模型存在准确率低下、计算存储高与量化误差的问题,CVPR 2024论文《Spatial-Aware Regression for Keypoint Localization》(Highlight)提出了一个高效的空间感知回归模型,用来准确定位人体关键点。空间感知回归模型的核心是将输入图像中的空间位置信息引入到回归过程中,降低直接回归的难度。引入的空间位置先验也能辅助模型感知不同实例的相同关键点,扩大了回归模型的适用范围。所提出的模型具有高性能、高效率的优点,在多个人体姿态估计任务,如二维/三维人体姿态估计、全身姿态估计以及多人姿态估计任务中均展现出领先的性能。例如在人体姿态估计数据集 COCO Keypoint 上,本文所提出的关键点定位模型在维持原有回归模型计算量的情况下提升了17.5%的定位准确率,取得了准确率与效率的平衡。
该论文第一作者为王东凯(北京大学),通讯作者为张史梁长聘副教授(北京大学/计算机学院视频与视觉技术研究所)。
二十六、 基于多模态参考的开放词汇识别

开放词汇识别旨在识别开放场景中的任意感兴趣类别或目标,赋予机器感知世界的通用视觉能力。现有的开放词汇识别方法主要通过向预训练视觉语言模型提供类别的文本描述来定义开放词汇分类器。文本的模糊性和歧义性等问题会导致生成的开放词汇分类器无法充分表征类别,影响开放词汇识别的准确性。为了解决这一问题,CVPR 2024论文《OVMR: Open-Vocabulary Recognition with Multi-Modal References》提出了基于多模态参考的开放词汇识别方法。该方法首先利用多模态分类器生成模块将多张示例图像融合成视觉令牌,并进一步使用语言编码器动态融合视觉令牌和文本令牌,生成了开放词汇多模态分类器。为了削弱低质量图像或文本对于多模态分类的负面影响,基于偏好的融合模块复用示例图像来评估各类别对单模态视觉文本分类器及多模态分类器的偏好,并基于偏好权重动态融合各分类器,形成最终的高质量的融合分类器。所提出的方法具有良好的泛化性,可即插即用至开放词汇分类和检测等任务中,无需额外微调便可在众多的下游任务中取得领先的性能。例如,在11个开放词汇分类任务上取得了82.34%的平均准确率,超过只依赖文本的基线方法13%,并在使用相同多模态数据的实验设置下超过了依赖微调的提示学习微调方法CoCoOp 1.87%。此外,在开放词汇检测LVIS数据集上,此方法检测精度超过第二名MM-OVOD 1.9%。
该论文第一作者为马泽红(北京大学),通讯作者为张史梁长聘副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括魏龙辉博士(华为)和田奇博士(华为)。
二十七、 基于梯度范数正则化的无参考图像质量模型对抗攻击的防御手段

无参考图像质量评价(NR-IQA)是一项在无需参照原始、未受损害图像的情况下,对图像质量进行评估的任务。这种评估在诸如视频压缩、图像恢复和图像生成等多媒体领域有着广泛的应用。尽管近年来已经推出了多种NR-IQA模型,但它们都面临一个共同的挑战:易受对抗性攻击的影响。对抗性攻击是指通过利用NR-IQA模型的漏洞,对输入图像添加微小的、肉眼难以察觉的扰动,让NR-IQA模型在对图像质量的打分上出现大幅度偏差。为了应对这个问题,CVPR 2024论文《Defense Against Adversarial Attacks on No-Reference Image Quality Models with Gradient Norm Regularization》在NR-IQA领域首次提出了一种防御策略。这种策略通过减小模型梯度的L1范数提高模型对微小扰动的稳定性,以增强模型的鲁棒性。理论分析显示,模型对输入图像的评价分数变化幅度以模型关于输入图像梯度的ℓ1范数为上界。因此,该文章提出了一种范数正则化训练策略,通过正则化项约束梯度的ℓ1范数,增强模型的鲁棒性。实验结果证明,这种训练策略可以有效地减少模型在对抗性攻击下的预测分数变化,提高了模型的防御能力。该文章是首次尝试防御NR-IQA模型的对抗性攻击,对于提高图像质量评价模型的安全性,具有重要的意义。
该论文共同第一作者为刘俣伽(北京大学)和杨晨曦(北京大学),通讯作者为蒋婷婷副教授(北京大学/计算机学院视频与视觉技术研究所),合作作者包括李鼎权(鹏城实验室)和丁健豪(北京大学)。
二十八、 面向真实场景去噪问题的高效自监督非对称盲点网络

自监督去噪网络由于其无需干净图像即可训练的能力而受到了广泛关注。然而,真实世界场景中的噪声往往是空间相关的,这导致许多假设像素间噪声独立的自监督算法表现不佳。最近的研究试图通过下采样或邻域掩蔽来打破噪声相关性。然而,在下采样子图上进行去噪可能导致由于采样率降低而产生的混叠效应和细节丢失。此外,邻域掩蔽方法要么计算复杂度高,要么在推理过程中不考虑局部空间信息的留存率。通过分析现有方法,可以看出在现实世界的自监督去噪任务中获得高质量和纹理丰富的结果的关键是,在原始输入分辨率结构上训练,并在训练和推理期间使用非对称操作。基于此,CVPR 2024论文《Exploring Asymmetric Tunable Blind-Spots for Self-supervised Denoising in Real-World Scenarios》提出了非对称可调盲点网络(AT-BSN),其中盲点大小可以自由调整,从而在训练和推理期间更好地平衡噪声相关性抑制和图像局部空间破坏。此外,所提出方法将预训练的AT-BSN视为一个元教师网络,能够通过采样不同的盲点生成各种教师网络。训练时采用了一种基于盲点的多教师蒸馏策略,以蒸馏一个轻量级网络,显著提高性能。在多个数据集上的实验结果证明所提出方法达到了最先进的水平,并在计算开销和视觉效果方面显著优于其他自监督算法。
该论文所有作者均来自于北京大学,第一作者为陈世炎,通讯作者为余肇飞助理教授(北京大学/人工智能研究院;计算机学院视频与视觉技术研究所),合作作者包括张济远和黄铁军教授。
二十九、 高速场景中未知时空对齐的跨模态脉冲引导运动去模糊算法
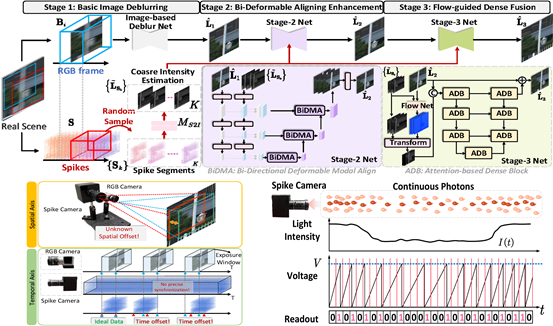
传统的基于帧的相机依赖曝光窗口成像,在高速场景中会出现运动模糊。基于帧的去模糊方法缺乏可靠的运动线索,难以在极端模糊条件下恢复清晰图像。脉冲相机是一种新型的神经形态视觉传感器,能够输出具有超高时间分辨率的脉冲流,它可以补充传统相机中丢失的时间信息,并指导运动去模糊。然而,在实际场景中,由于校准坐标的复杂性、拍摄过程产生振动而造成的设备位移和时间轴偏移,将离散的RGB图像和连续的脉冲流在时间和空间轴上对齐是一个挑战。像素的错位会导致去模糊效果严重下降。为解决此问题,CVPR 2024论文《Spike-guided Motion Deblurring with Unknown Modal Spatiotemporal Alignment》提出了一种在未知脉冲和图像时空对齐情况下的脉冲引导运动去模糊框架,并设计了包含基础模糊消除网络、双向可变形对齐模块和基于光流的多尺度融合模块的三阶段网络。实验结果表明,所提出方法可以在未知对齐情况下有效地指导图像去模糊,超越其他方法的性能。
该论文所有作者均来自于北京大学,第一作者为张济远,通讯作者为余肇飞助理教授(北京大学/人工智能研究院;计算机学院视频与视觉技术研究所)和郑雅菁博士后,合作作者包括陈世炎和黄铁军教授。
三十、 强度鲁棒的脉冲相机自动对焦方法
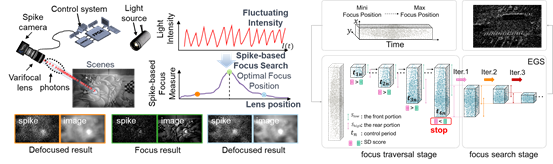
自动对焦控制对于相机有效的捕捉场景信息十分关键。然而,由于脉冲相机记录的脉冲流与图像流、事件流在场景信息表征上存在差异,目前缺乏针对脉冲相机设计的自动对焦方法,使得其难以实现高速对焦以及高对比度成像。为了解决这一挑战,CVPR 2024论文《Intensity-Robust Autofocus for Spike Camera》提出了一种基于脉冲流的自动对焦方案,包括针对脉冲流设计的对焦度量——脉冲散度和相应的快速对焦搜索策略——基于脉冲流的黄金快速搜索。该方案可以实现快速的合焦,且无需对变焦镜头的整个调焦范围进行遍历。为了验证所提方法的性能,收集了一个基于脉冲流的自动对焦数据集,其中包含不同场景亮度和运动场景下的合成数据和真实数据。在这些数据上的实验结果表明,所提方法在准确性和效率上超越了其他方法。此外,在不同场景亮度下捕获的数据上的实验说明了所提方法在自动对焦过程中对光照强度变化的鲁棒性。
该论文第一作者为苏长青(北京大学)和肖永生(南昌航空航天大学),通讯作者为熊博(北京大学),合作作者包括叶志远(南昌航空航天大学)、周游(南京大学)、程振(清华大学)、余肇飞助理教授(北京大学/人工智能研究院;计算机学院视频与视觉技术研究所)和黄铁军教授(北京大学)。
三十一、 基于三维逐点对应关系的可泛化衣服操作
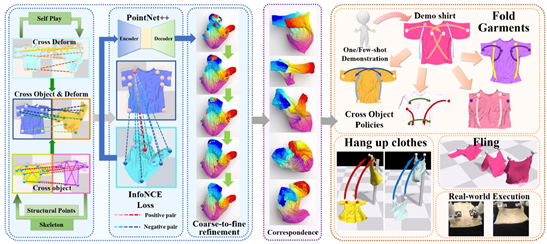
衣物操作(例如展开、折叠和挂衣服)对于未来机器人完成家庭助手任务至关重要,但由于衣物类型(如上衣、裤子、裙子)、几何形状和形变的多样性,这项任务极具挑战性。尽管先前的研究能够在特定任务中操作形状相似的衣物,但它们大多需要为不同任务设计不同的策略,无法推广到几何形状多样的衣物上,并且通常严重依赖人工标注的成功策略。为了解决上述问题,提升衣服操作的可泛化性、减少对人工标注的依赖,CVPR 2024论文《UniGarmentManip: A Unified Framework for Category-Level Garment Manipulation via Dense Visual Correspondence》提出利用衣物在特定类别中具有相似结构的特性,通过自监督学习方法,学习同一类别中具有不同变形的衣物之间的拓扑稠密(逐点级,point-level)视觉对应关系。这种拓扑对应关系可以轻松适应功能对应关系,从而指导各种下游任务的操作策略,仅需一次或几次示范。所提出方法在三类不同类别的衣物上进行了实验,涉及三种具有代表性的任务,在多种场景中使用单臂或双臂操作,进行一步或多步操作,处理平整或凌乱的衣物,验证了所提出方法的有效性。
该论文的共同第一作者是吴睿海(北京大学)和鲁浩然(北京大学),通讯作者为董豪助理教授(北京大学/计算机学院前沿计算研究中心),合作作者包括王一言(北京理工大学)和王昱博(北京大学)。
三十二、 针对物体为中心的的机器人操作多模态大模型
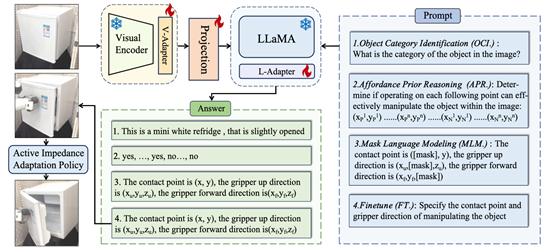
机器人操作依赖于准确预测接触点和末端执行器的方向,以确保操作成功。然而,基于学习的机器人操作如果仅在模拟器中针对有限类别进行训练,往往难以实现广泛的泛化,特别是在面对大量类别时。因此,CVPR 2024论文《ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation》提出了一种创新的机器人操作方法,利用多模态大型语言模型(MLLMs)的强大推理能力来增强操作的稳定性和泛化能力。通过微调注入的适配器,保留了MLLMs固有的常识和推理能力,同时赋予它们操作的能力。关键在于引入的微调范式,涵盖了对象类别理解、可操纵(affordance)先验推理和以对象为中心的姿态预测,以激发MLLM在操作中的推理能力。在推理过程中,所提出方法利用RGB图像和文本提示以chain-of-thought的方式预测末端执行器的姿态。在建立初始接触后,引入了主动阻抗适应策略,以闭环方式规划接下来的路径点。此外,在现实世界中,设计了一种用于操作的测试时适应(TTA)策略,使模型能够更好地适应当前的实际场景配置。
该论文第一作者为李晓琦(北京大学),通讯作者为董豪助理教授(北京大学/计算机学院前沿计算中心),合作作者包括沈妍(北京大学)、龙宇星(北京大学)、刘家铭(北京大学)、张明旭(北京邮电大学)和张仁睿(香港中文大学)。
三十三、 利用非参数网络进行少样本3D场景分割
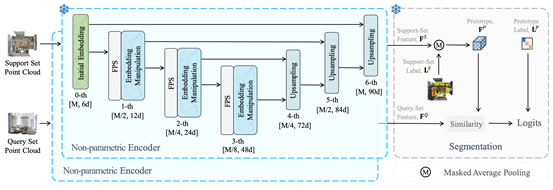
为了减少对大规模数据集的依赖,最近在3D分割领域的研究开始借助少样本学习。目前的3D少样本分割方法首先在“已见”类上进行预训练,然后评估它们在“未见”类上的泛化性能。然而,先前的预训练阶段不仅引入了过多的时间开销,还在“未见”类上产生了显著的领域差距。为了解决这些问题,CVPR 2024论文《No Time to Train: Empowering Non-Parametric Networks for Few-shot 3D Scene Segmentation》(Highlight)提出了一种用于少样本3D分割的非参数网络Seg-NN及其参数化变体Seg-PN。Seg-NN无需训练,通过手工设计的滤波器提取稠密表示,其性能与现有的参数化模型相当。由于消除了预训练,Seg-NN能够减轻领域差距问题并节省大量时间。基于Seg-NN,Seg-PN仅需训练一个轻量级的查询-支持传输(QUEST)模块,该模块增强了支持集和查询集之间的交互。实验表明,Seg-PN在S3DIS和ScanNet数据集上分别比之前的最先进方法提高了4.19%和7.71%的mIoU,同时减少了90%的训练时间,显示出其有效性和高效性。
该论文第一作者为朱向阳(上海人工智能实验室),合作作者包括张仁瑞(港中文)、董豪助理教授(北京大学/计算机学院前沿计算中心)、刘家铭(北京大学)和高鹏(上海人工智能实验室)。
三十四、 基于掩码聚类的开放词汇三维语义分割
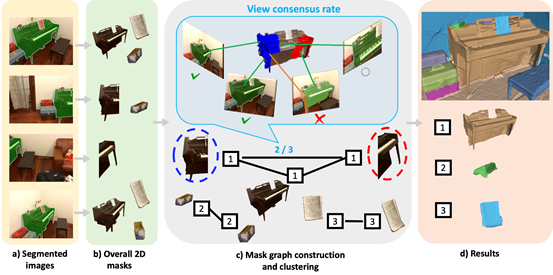
开放词汇的三维实例分割是机器人感知未知场景的第一步,也是AR/VR应用中进行场景编辑的第一步,有着重要应用价值。然而,由于三维数据标注和采集困难,目前缺乏大规模的细粒度三维实例标注。为了解决这一问题,已有研究首先借助二维实例分割模型生成二维掩码,再根据相邻帧之间计算的度量将它们合并成3D实例。与这些局部度量不同,CVPR 2024论文《MaskClustering: View Consensus based Mask Graph Clustering for Open-Vocabulary 3D Instance Segmentation》提出了一种新的度量方法,即view consensus rate,以增强对多视角交互验证的利用。对于两个二维掩码,如果大量其他视角的2D掩码同时包含这两个2D掩码,那么这两个2D掩码应被视为同一3D实例的一部分,应该被合并。这个被包含的比例被称为view consensus rate,并以此为边的权重,构建了一个全局掩码图,其中每个掩码是一个节点。通过对高view consensus rate的掩码进行迭代聚类,生成了一系列掩码类,每个掩码类代表一个独特的3D实例。本文提出的方法无需任何训练,即可在常用数据集ScanNet++、ScanNet以及MatterPort3D上取得了远超前人工作的精度。
该论文所有作者均来自于北京大学,第一作者为严汨,通讯作者为王鹤助理教授(北京大学/计算机学院前沿计算中心),合作作者包括张嘉曌和朱炎。
三十五、 类别级多部件多关节三维形状装配
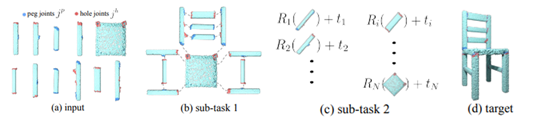
形状装配是通过排列简单的几何部件来组成复杂的形状几何体,被广泛应用于机器人自动装配和计算机辅助设计(CAD)建模。现有的论文侧重于几何推理,忽略了现实中连接不同接触面的关节的物理匹配和装配的过程。成功的关节优化装配需要满足形状结构和关节对齐的双重目标。基于此,CVPR 2024论文《Category-Level Multi-Part Multi-Joint 3D Shape Assembly》提出了一种由两个层级的图表示学习组成的分级图学习方法,将接触关节考虑到多部分装配任务中。一部分图以部件几何形状为输入来构建所需的形状结构,另一部分关节级图使用部件关节信息,侧重于匹配和对齐关节,结合这两种信息来实现结构和关节对齐的双重目标。大量实验表明,所提出方法优于以往的方法,取得了更好的形状结构和更高的关节对齐精度。
该论文第一作者及通讯作者为Yichen Li(斯坦福大学),合作作者包括Kaichun Mo(英伟达)、段岳圻(清华大学)、王鹤(北京大学/计算机学院前沿计算中心)、Jiequan Zhang(斯坦福大学)、Lin Shao(新加坡国立大学)、Wojciech Matusik(麻省理工学院计算机科学与人工智能实验室)和Leonidas Guibas(斯坦福大学)。
三十六、 结构引导的扩散模型对抗训练方法
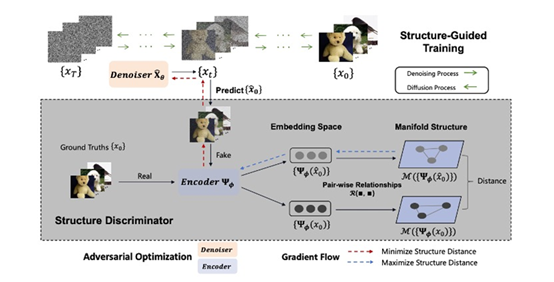
扩散模型在各种生成应用中展示了强大的能力。现有方法主要通过最小化加权的去噪得分匹配损失来进行数据分布建模,但其训练主要强调实例级优化,忽略了每个小批量中有价值的流形结构信息,而这些信息可以有效建模样本之间的成对关系。为了解决这一局限性,CVPR 2024论文《Structure-Guided Adversarial Training of Diffusion Models》引入了结构引导的扩散模型对抗训练方法(SADM)。在这一开创性方法中,让模型学习每个训练批次中样本之间的流形结构。为了确保模型捕捉到数据分布中的真实流形结构,提出使用对抗式训练方法优化扩散模型生成器,设计鉴别器区分真实流形结构和生成的流形结构。SADM显著改进了现有的扩散模型,并在12个数据集的图像生成和跨域微调任务中超越了现有方法。其中,在ImageNet上以256×256和512×512分辨率进行条件图像生成,分别获得了1.58和2.11的当前最优级别的FID分数。
该论文所有作者均来自于北京大学,第一作者为杨灵,通讯作者为崔斌教授(北京大学/计算机学院数据科学与工程研究所),其他合作作者均为崔斌教授PKU-DAIR课题组实习生。
三十七、 TimeChat: 针对长视频时序定位任务的视频大语言模型
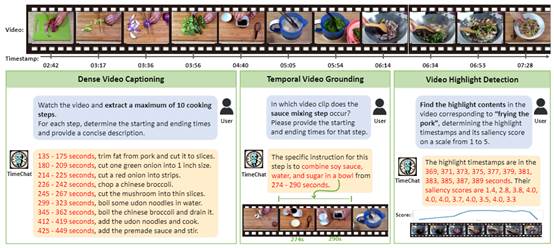
CVPR 2024论文《TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding》旨在构建一个通用的、对时序敏感的视频大模型TimeChat。该模型可以依据用户输入的指令,完成对视频的关键事件摘要、时序定位、高光检测等一系列时序敏感任务。该模型包含两个关键模块:(1)融合时间戳信息的视频帧编码器:用于将每帧的视觉内容与该帧的时间戳绑定;(2)基于滑动窗口的视频 Q-Former:用于生成变长的视频token序列,以适应各种时长的视频输入。此外,本文构建了一个指令微调数据集,包括 6 个任务和 12.5 万个训练样本,以进一步增强 TimeChat 的指令遵循性能。实验结果表明,TimeChat在多种视频任务上展示了强大的零样本时序定位和推理能力。例如,与之前最先进的视频大模型相比,TimeChat在YouCook2上将F1 score和CIDEr分别提升9.2 和2.8;在QVHighlights上将HIT@1提升5.8;在Charades-STA上将R@1(IoU=0.5)提升27.5。
该论文共同第一作者为任抒怀(北京大学)和姚林丽(北京大学),通讯作者为孙栩长聘副教授(北京大学/计算机学院计算语言学研究所),合作作者包括李世成(北京大学)和侯璐(华为)。
三十八、 基于松弛匹配和归因区域对齐的对抗蒸馏

对抗蒸馏是一种有效提高小型模型鲁棒性的方法。与预期相反,性能卓越的教师模型并不总能训练出更为鲁棒的学生模型,主要原因有两方面。首先,当教师模型和学生模型在预测结果上存在显著差异时,使用KL散度进行预测值的精确匹配会干扰训练过程,导致现有方法的性能下降。其次,仅基于输出结果进行匹配,限制了学生模型对教师模型行为的全面理解。为了解决这些问题,CVPR 2024论文《Adversarial Distillation Based on Slack Matching and Attribution Region Alignment》提出了一种名为SmaraAD的新型对抗蒸馏方法。在训练过程中,该方法通过将学生模型关注的归因区域与教师模型的归因区域对齐,促进学生模型更好地理解教师模型的行为。同时,采用更加松弛的匹配方法代替KL散度,提高训练效果。大量实验结果验证了所提出方法在提升小型模型准确性和鲁棒性方面的有效性。
该论文的第一作者是尹晟霖(北京大学),通讯作者是肖臻研究员(北京大学/计算机学院元宇宙技术研究所),合作作者包括宋明轩(北京大学)和隆杰毅(Theta Labs, Inc.)。
论文来源:
[1] Xinyu Zhou, Peiqi Duan, Boyu Li, Chu Zhou, Chao Xu, and Boxin Shi. EvDiG: Event-guided Direct and Global Components Separation. In Proc. CVPR 2024 (Oral).
[2] Bohan Yu, Jieji Ren, Jin Han, Feishi Wang, Jinxiu Liang, Boxin Shi. EventPS: Real-Time Photometric Stereo using an Event Camera. In Proc. CVPR 2024 (Oral).
[3] Fan Fei, Jiajun Tang, Ping Tan, and Boxin Shi. VMINer: Versatile Multi-view Inverse Rendering with Near- and Far-field Light Sources. In Proc. CVPR 2024 (Highlight).
[4] Yixin Yang, Jinxiu Liang, Bohan Yu, Yan Chen, Jimmy Ren, Boxin Shi. Learning Latency Correction for Event-guided Deblurring and Frame Interpolation. In Proc. CVPR 2024.
[5] Yakun Chang, Yeliduosi Xiaokaiti, Yujia Liu, Bin Fan, Zhaojun Huang, Tiejun Huang, and Boxin Shi. Towards HDR and HFR Video from olling-mixed-bit Spikings. In Proc. CVPR 2024.
[6] Haofeng Zhong, Yuchen Hong, Shuchen Weng, Jinxiu Liang, and Boxin Shi. Language-guided Image Reflection Separation. In Proc. CVPR 2024.
[7] Yifei Xia, Chu Zhou, Chengxuan Zhu, Minggui Teng, Chao Xu, and Boxin Shi. NB-GTR: Narrow-band guided Turbulence Removal. In Proc. CVPR 2024.
[8] Jianping Jiang, Xinyu Zhou, Bingxuan Wang, Xiaoming Deng, Chao Xu, and Boxin Shi. Complementing Event Streams and RGB Frames for Hand Mesh Reconstruction. In Proc. CVPR 2024.
[9] Yunkai Tang, Chengxuan Zhu, Renjie Wan, Chao Xu, and Boxin Shi. Neural Underwater Scene Representation. In Proc. CVPR 2024.
[10] Heng Guo, Jieji Ren, Feishi Wang, Boxin Shi, Mingjun Ren, and Yasuyuki Matsushita. DiLiGenRT: A Photometric Stereo Dataset with Quantified Roughness and Translucency. In Proc. CVPR 2024.
[11] Ziqi Cai, Kaiwen Jiang, Shu-Yu Chen, Yu-Kun Lai, Hongbo Fu, Boxin Shi, Lin Gao. Real-time 3D-aware Portrait Video Relighting. In Proc. CVPR 2024 (Highlight).
[12] Yufei Han, Heng Guo, Koki Fukai, Hiroaki Santo, Boxin Shi, Fumio Okura, Zhanyu Ma, Yunpeng Jia. NeRSP: Neural 3D Reconstruction for Reflective Objects with Sparse Polarized Images. In Proc. CVPR 2024.
[13] Zongrui Li, Zhan Lu, Haojie Yan, Boxin Shi, Gang Pan, Qian Zheng, Xudong Jiang. Spin-UP: Spin Light for Natural Light Uncalibrated Photometric Stereo. In Proc. CVPR 2024.
[14] Rui Zhao, Ruiqin Xiong, Jing Zhao, Jian Zhang, Xiaopeng Fan, Zhaofei Yu, Tiejun Huang. Boosting Spike Camera Image Reconstruction from a Perspective of Dealing with Spike Fluctuations. In Proc. CVPR 2024.
[15] Yanchen Dong, Ruiqin Xiong, Jian Zhang, Zhaofei Yu, Xiaopeng Fan, Shuyuan Zhu, Tiejun Huang. Super-Resolution Reconstruction from Bayer-Pattern Spike Streams. In Proc. CVPR 2024.
[16] Yuan Zhang, Tao Huang, Jiaming Liu, Tao Jiang, Kuan Cheng, Shanghang Zhang. FreeKD: Knowledge Distillation via Semantic Frequency Prompt. In Proc. CVPR 2024.
[17] Guanqun Wang, Jiaming Liu, Chenxuan Li, Yuan Zhang, Junpeng Ma, Xinyu Wei, Kevin Zhang, Maurice Chong, Renrui Zhang, Yijiang Liu, Shanghang Zhang. Cloud-Device Collaborative Learning for Multimodal Large Language Models. In Proc. CVPR 2024.
[18] Jiaming Liu, Ran Xu, Senqiao Yang, Renrui Zhang, Qizhe Zhang, Zehui Chen, Yandong Guo, Shanghang Zhang. Continual-MAE: Adaptive Distribution Masked Autoencoders for Continual Test-Time Adaptation. In Proc. CVPR 2024.
[19] Zhi Zhang, Qizhe Zhang, Zijun Gao, Renrui Zhang, Ekaterina Shutova, Shiji Zhou, and Shanghang Zhang. Gradient-based Parameter Selection for Efficient Fine-Tuning. In Proc. CVPR 2024.
[20] Xiaobao Wei, Renrui Zhang, Jiarui Wu, Jiaming Liu, Ming Lu, Yandong Guo, Shanghang Zhang, NTO3D: Neural Target Object 3D Reconstruction with Segment Anything. In Proc. CVPR 2024.
[21] Junyi Yao, Yijiang Liu, Zhen Dong, Mingfei Guo, Helan Hu, Kurt Keutzer, Li Du, Daquan Zhou, Shanghang Zhang. PromptCoT: Align Prompt Distribution via Adapted Chain-of-Thought. In Proc. CVPR 2024.
[22] Xingqun Qi, Jiahao Pan, Peng Li, Ruibin Yuan, Xiaowei Chi, Mengfei Li, Wenhan Luo, Wei Xue, Shanghang Zhang, Qifeng Liu, Yike Guo. Weakly-Supervised Emotion Transition Learning for Diverse 3D Co-speech Gesture Generation. In Proc. CVPR 2024.
[23] Shiyu Xuan, Qingpei Guo, Ming Yang, Shiliang Zhang. Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs. In Proc. CVPR 2024.
[24] Dongkai Wang, Shiyu Xuan, Shiliang Zhang. LocLLM: Exploiting Generalizable Human Keypoint Localization via Large Language Model. In Proc. CVPR 2024 (Highlight).
[25] Dongkai Wang, Shiliang Zhang. Spatial-Aware Regression for Keypoint Localization. In Proc. CVPR 2024 (Highlight).
[26] Zehong Ma, Shiliang Zhang, Longhui Wei, Qi Tian. OVMR: Open-Vocabulary Recognition with Multi-Modal References. In Proc. CVPR 2024.
[27] Yujia Liu, Chenxi Yang, Dingquan Li, Jianhao Ding, Tingting Jiang. Defense Against Adversarial Attacks on No-Reference Image Quality Models with Gradient Norm Regularization. In Proc. CVPR 2024.
[28] Shiyan Chen, Jiyuan Zhang, Zhaofei Yu and Tiejun Huang. Exploring Asymmetric Tunable Blind-Spots for Self-supervised Denoising in Real-World Scenarios. In Proc. CVPR 2024.
[29] Jiyuan Zhang, Shiyan Chen, YajingZheng, Zhaofei Yu, Tiejun Huang. Spike-guided Motion Deblurring with Unknown Modal Spatiotemporal Alignment. In Proc. CVPR 2024.
[30] Changqing Su, Zhiyuan Ye, Yongsheng Xiao, You Zhou, Zhen Cheng, Bo Xiong, Zhaofei Yu, Tiejun Huang. Intensity-Robust Autofocus for Spike Camera. In Proc. CVPR 2024.
[31] Ruihai Wu, Haoran Lu, Yiyan Wang, Yubo Wang, Hao Dong. UniGarmentManip: A Unified Framework for Category-Level Garment Manipulation via Dense Visual Correspondence. In Proc. CVPR 2024.
[32] Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Renrui Zhang, Jiaming Liu, Hao Dong. ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation. In Proc. CVPR 2024.
[33] Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyu Guo, Jiaming Liu, Han Xiao, Chaoyou Fu, Hao Dong, Peng Gao. No Time to Train: Empowering Non-Parametric Networks for Few-shot 3D Scene Segmentation. In Proc. CVPR 2024 (Highlight).
[34] Mi Yan, Jiazhao Zhang, Yan Zhu, He Wang, MaskClustering: View Consensus Based Mask Graph Clustering for Open-Vocabulary 3D Instance Segmentation. In Proc. CVPR 2024.
[35] Yichen Li, Kaichun Mo, Yueqi Duan, He Wang, Jiequan Zhang, Lin Shao, Wojciech Matusik, Leonidas Guibas. Category-Level Multi-Part Multi-Joint 3D Shape Assembly. In Proc. CVPR 2024.
[36] Ling Yang, Haotian Qian, Zhilong Zhang, Jingwei Liu, Bin Cui. Structure-Guided Adversarial Training of Diffusion Models. In Proc. CVPR 2024.
[37] Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, Lu Hou. TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding. In Proc. CVPR 2024.
[38] Shenglin Yin, Zhen Xiao, Mingxuan Song, Jieyi Long. Adversarial Distillation Based on Slack Matching and Attribution Region Alignment. In Proc. CVPR 2024.


