日前,第18届国际操作系统设计与实现大会 OSDI(USENIX Symposium on Operating Systems Design and Implementation)公布本年度文章录用情况,北京大学计算机学院作为第一作者单位共有3篇论文被录用,均来自软件研究所金鑫-刘譞哲团队。
OSDI与另一会议SOSP (ACM Symposium on Operating Systems Principles),是计算机操作系统领域最重要的两大国际会议,在国际上享有极高的学术声誉,也是CCF推荐的A类会议。本届会议共收到282篇论文投稿,录用49篇,录用率仅为17.8%。
3篇被录用论文中,2篇关注分布式机器学习系统的焦点—大模型的伺服系统,这是该团队近年来在继Muri(SIGCOMM 2022)、Mandheling (MobiCom 2022)、ElasticFlow(ASPLOS 2023)、TGS(NSDI 2023)、Rummy (NSDI 2024)后在机器学习系统领域的最新进展;1篇关注服务器无感知计算环境下的突发性块存储服务优化,是团队继Halfmoon (SOSP 2023)、dRAID (ASPLOS 2023)、XRON (SIGCOMM 2023)、FaaSLight (TOSEM 2023)、Jolteon(NSDI 2024) 之后在服务器无感知计算方向的探索尝试。
以下是3篇文章的介绍。
(一) dLoRA:面向多dLoRA大模型推断的动态编排服务系统
近年来,大型语言模型(LLM)的推断(inference)服务受到了广泛关注。然而,现有的推断系统在同时服务多个LoRA大模型时,存在同时服务多类请求资源利用率低以及负载不均的问题。为此,论文《dLoRA: Dynamically Orchestrating Requests and Adapters for LoRA LLM Serving》提出了一套多LoRA大模型的动态编排系统,旨在通过动态编排请求和LoRA适配器,提升LoRA大模型推断服务的效率。在实例层面,dLoRA根据请求分布动态在多类LoRA推断策略切换,实现计算效率和等待时长之间的更优权衡。在集群层面,dLoRA通过选择性预先加载LoRA adapter以及动态进行请求和LoRA adapter的协同迁移,实现集群层面负载均衡。实验结果表明,dLoRA相比单模型版本vLLM和HuggingFace PEFT提升吞吐至多50.7倍和30.5倍,相比同期工作S-LoRA,dLoRA可降低延迟至多1.8倍。该论文的第一作者为北京大学计算机学院2022级直博生吴秉阳(导师金鑫长聘副教授),作者包括北京大学朱睿冬、章梓立,上海人工智能实验室孙鹏,北京大学刘譞哲教授(通讯作者)和金鑫长聘副教授。
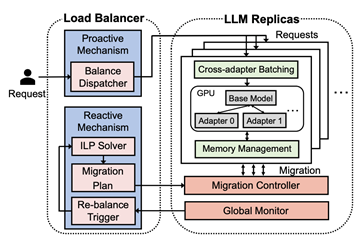
图 1 dLoRA系统架构
(二) DistServe:预填充和解码解耦合的大模型推断服务系统
随着大型语言模型(LLM)的兴起,其推断系统的优化得到广泛关注。然而,现有的大语言模型推断系统在同时服务多个请求时,存在预填充与解码阶段相互干扰以及资源分配耦合的问题。为此,论文《DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving》提出了一套将预填充与解码计算解耦分离的系统,旨在通过为两个阶段动态调整资源分配与并行策略,优化LLM推断服务的性能。DistServe系统在实例层面将预填充和解码计算分配到不同的GPU上,消除了两者之间的干扰,并根据应用的TTFT和TPOT要求,协同优化资源分配和并行策略,以满足不同阶段的特定延迟要求。实验结果表明,在多种流行LLM、应用和延迟要求下,相较于现有的系统,DistServe在保证90%以上请求延迟约束的情况下最多可以处理7.4倍的请求,或实现12.6倍的更严格延迟要求。该论文的第一作者为北京大学计算机学院2022级直博生仲殷旻(导师金鑫长聘副教授),作者包括北京大学的本科生刘胜与和胡建波,加州大学圣地亚哥分校的博士生陈俊达和张昊助理教授,北京大学刘譞哲教授和金鑫长聘副教授(通讯作者)。
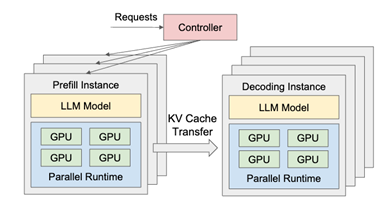
图 2 DistServe 系统结构
(三) BustCBS:基于DPU、支持突发性块存储服务的云计算系统
块存储是云计算的重要组成部分。目前,通过DPU(data processing unit)对存储进行虚拟化以及支持块存储进行突发已经成为块存储产品的常见做法。通过对阿里云块存储系统的观察与测量,我们发现运行在DPU上的存储虚拟化软件是多租户块存储性能波动的主要来源。我们进一步发现,块存储对突发I/O的支持进一步加剧了租户间的性能扰动。为了解决这一问题,论文《Burstable Cloud Block Storage with Data Processing Units》提出了支持突发、软硬件协同优化的I/O调度系统BurstCBS。BurstCBS充分利用DPU上的FPGA实现了多个线程间的负载均衡,并在每个线程上对租户可获得的资源进行合理分配。具体来说,BurstCBS采用了三个思路:(一)通过高性能的队列扩展技术在不影响性能的前提下支持I/O在多线程间均匀分配;(二)通过支持突发的I/O调度算法在允许租户突发的同时保护低流量租户的服务质量;(三)通过向量化的开销估算器准确描述I/O的资源开销。论文扩展了阿里云现有的块存储虚拟化软件实现了BurstCBS,并使用多种存储负载对其进行了评估。实验结果显示,相比于现有方案,BurstCBS在其他租户突发时可为低流量租户降低85%的延迟和提升5倍的吞吐。该论文第一作者为北京大学计算机学院2021级博士生舒俊宜(导师为梅宏院士),作者包括阿里云高级技术专家钱坤,阿里云资深技术专家、网络研究团队负责人翟恩南,北京大学刘譞哲教授,北京大学金鑫长聘副教授(通讯作者)。
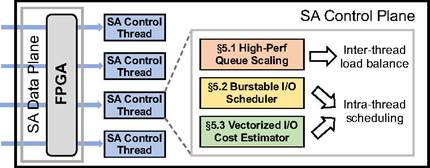
图 3 BurstCBS系统结构
相关阅读:
北大团队,打造AI时代的软件基座:
https://mp.weixin.qq.com/s/aLaahSH95qzg0wPOvVnzLg


