一、成果简介
本团队聚焦于大模型训练与推理的核心技术攻关,围绕国产硬件的高效适配、超大规模模型的并行训练和低延迟推理部署,构建了覆盖多场景的端到端AI大模型系统框架,显著提升了模型在性能、可控性与生态兼容性方面的整体能力。
在模型训练方面,团队面向百亿级以上参数规模的预训练语言及多模态模型,提出融合数据并行、流水线并行与ZeRO冗余优化的混合并行训练策略,并开发适配国产AI加速芯片(如昇腾、寒武纪)的高效稳定训练流程,实现跨可用区的高性能训练,同时构建了针对张量并行与MoE专家并行通信需求的国产优化方案,在能效比和稳定性上超过主流NVIDIA平台。在推理部署方面,针对大模型的内存瓶颈与延迟问题,提出分层量化、权重裁剪与KV缓存优化相结合的轻量化方案,开发适配国产芯片架构的推理编译与运行时优化组件和高效算子。此外,团队还构建了异构算力协同的通信框架,支持国产多厂商GPU之间的动态路径选择与弹性资源调度,显著提升了大规模异构集群下训练与推理任务的吞吐能力和通信效率。
依托上述技术积累,团队构建了完整适配国产生态的大模型训练与推理平台,并在多个实际场景中完成落地验证,有效支撑了高可信、高效率、可持续的大模型国产替代路径,为我国人工智能核心技术的自主可控奠定了坚实基础。
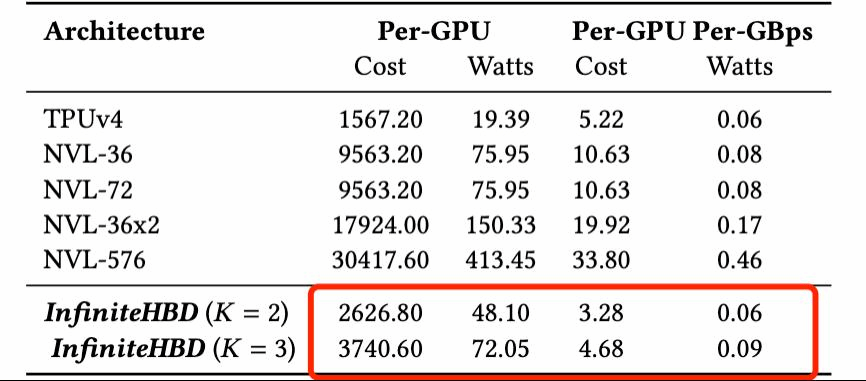
例1: 国产训练技术对标NVIDIA平台的性能评估
每个研究方向的代表性成果介绍:https://grace-liu.github.io/pub.html
二、应用领域和市场前景
随着人工智能从感知智能向认知智能演进,千亿级大模型正逐步成为产业智能化升级的通用底座,但当前主流大模型严重依赖海外软硬件生态,面临算力可控性差、模型安全性不足、部署成本高等问题,制约了其在我国关键领域的应用。近年来,国家密集出台政策文件,明确提出建设自主可控的人工智能基础设施,推动国产AI技术与产业深度融合,并配套专项资金和政策支持,为国产大模型生态发展创造了良好环境。
本研究团队研发的大模型训练与推理平台,基于国产算力架构的深度适配与优化,构建了高效、低成本、安全可控的全栈AI解决方案,显著降低了国产平台上大模型的部署与应用门槛。平台模块化程度高,适配大语言模型、多模态生成模型、领域定制模型,并支持边缘设备、私有云、政务内网等多类终端环境。随着国产AI芯片、操作系统与开发框架的持续完善,该平台将在数字政府、企业办公、教育科研、工业智能、国防安全等领域释放更大潜力,为保障国家数据安全、推动数字经济发展和构建可信AI生态发挥关键作用,具有广阔的市场前景与战略价值。
三、合作方式
合作开发、技术服务和咨询、技术转让。
对接方式
1.合作意向方联系北京大学计算机学院产学研合作办公室;
2.产学研合作办公室沟通了解意向方情况;
3.会同成果完成团队与意向方共同研讨合作方案。
北京大学计算机学院产学研合作办公室
邮箱:hecheng1213@pku.edu.cn
未经授权,请勿转载


